我想將我的 XML 檔案轉換為資料框熊貓我試過這段代碼
import pandas as pd
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("C:/Users/user/Desktop/essai/dataXml.xml", "r"),"xml")
d = {}
for tag in soup.RECORDING.find_all(recursive=False):
d[tag.name] = tag.get_text(strip=True)
df = pd.DataFrame([d])
print(df)
這是我的 XML 資料的一部分
<?xml version="1.0" encoding="utf-8"?>
<sentences>
<sentence>
<text>We went again and sat at the bar this time, I had 5 pints of guinness and not one buy-back, I ordered a basket of onion rings and there were about 5 in the basket, the rest was filled with crumbs, the chili was not even edible.</text>
<aspectCategories>
<aspectCategory category="place" polarity="neutral"/>
<aspectCategory category="food" polarity="negative"/>
</aspectCategories>
</sentence>
</sentences>`
我收到了這個錯誤
for tag in soup.RECORDING.find_all(recursive=False):
AttributeError: 'NoneType' object has no attribute 'find_all'
我該如何解決?
提前謝謝你
編輯:替換soup.RECORDING.find_all為soup.find_all修復了錯誤,但我仍然沒有得到我想要的
我想要這樣的東西
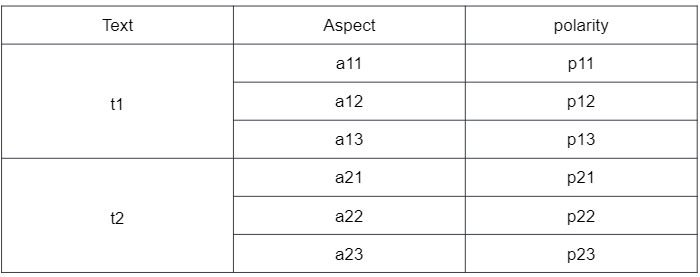
uj5u.com熱心網友回復:
試試這個代碼:
d = {
'text': [],
'aspect': [],
'polarity': []
}
for sentence in soup.find_all('sentence'):
text = sentence.find('text').text
for ac in sentence.find_all('aspectCategory'):
d['text'].append(text)
d['aspect'].append(ac.get('category'))
d['polarity'].append(ac.get('category'))
df = pd.DataFrame(d)
輸出:
>>> df
text aspect polarity
0 We went again and sat at the bar this time, I ... place place
1 We went again and sat at the bar this time, I ... food food
uj5u.com熱心網友回復:
考慮新的pandas 1.3.0 方法,read_xml但是join對不同級別節點的兩次呼叫。默認parser是lxml但是可以使用內置的etree來避免第三方的 XML 包。
import pandas as pd
import xml.etree.ElementTree as et
xml_file = "C:/Users/user/Desktop/essai/dataXml.xml"
doc = et.parse(xml_file)
df_list = [
(pd.read_xml(xml_file, xpath=f".//sentence[{i}]", parser="etree")
.join(pd.read_xml(
xml_file,
xpath=f".//sentence[{i}]/aspectCategories/*",
parser="etree"
))
) for i, s in enumerate(doc.iterfind(".//sentence"), start=1)
]
df = pd.concat(df_list)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/366344.html