使用:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0,3,(100000,5000)))
df = df.loc[:, (df != 0).any(axis=0)]
對于非常大的(1000000x2000)資料幀來說,擺脫僅包含零的列太慢了。任何建議如何加快速度?
謝謝
uj5u.com熱心網友回復:
眾所周知,Numpy 的運行速度比Pandas快得多。
因此,要發現哪些列僅包含零,請使用:
np.all(np.equal(df.values, 0), axis=0)
但是您的任務是將這些列放在DataFrame 中,就像我想的那樣,保留源列名稱。
因此,必須使用上述檢查的loc和否定結果對源 Dataframe 執行實際洗掉。
就像是:
df = df.loc[:, ~np.all(np.equal(df.values, 0), axis=0)]
uj5u.com熱心網友回復:
使用Numba有一種更快的方法來實作它。
事實上,大多數 Numpy 實作將創建巨大的臨時陣列,這些陣列填充和讀取都很慢。此外,Numpy 將遍歷整個資料幀,而這通常不需要(至少在您的示例中)。關鍵是您可以非常快速地知道是否需要通過迭代檢查列值來保留列,如果有任何 0(通常在開頭),則提前停止當前列的計算。此外,沒有必要總是復制整個資料幀(使用大約 1.9 GiB 的記憶體):當所有列都被保留時。最后,您可以并行執行計算。
但是,存在對性能至關重要的低級捕獲。首先,Numba 無法處理 Pandas 資料幀,但轉換為 Numpy 陣列幾乎是免費的df.values(同樣的事情適用于創建新資料幀)。此外,關于陣列的記憶體布局,最好在最內層回圈中的行或列上進行迭代。
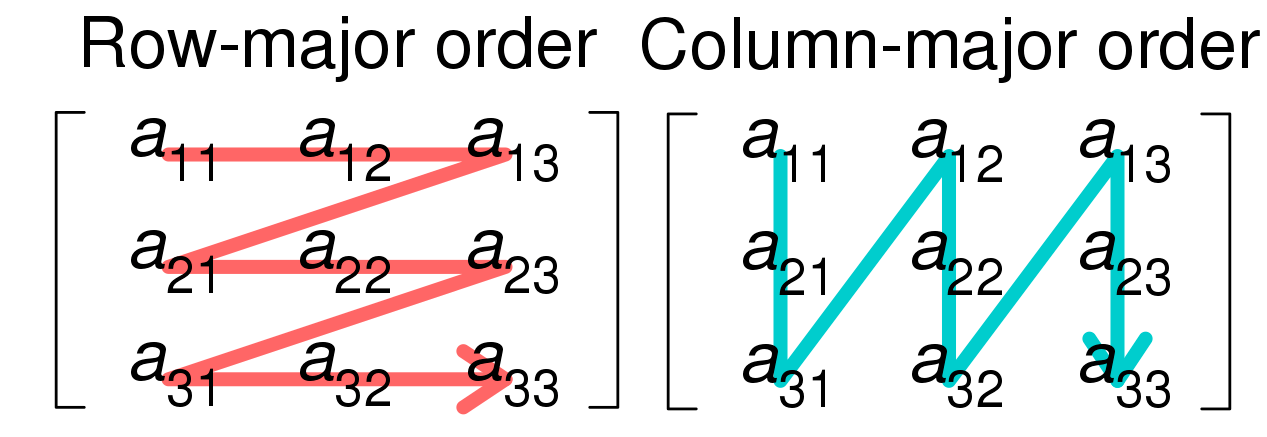
可以通過檢查輸入資料幀 Numpy 陣列的步幅來獲取此布局。
請注意,由于(不尋常的)Numpy 隨機初始化,該示例使用行主資料幀,但大多數資料幀往往是列主資料。
這是一個優化的實作:
import numba as nb
@nb.njit('int_[:,:](int_[:,:])', parallel=True)
def filterNullColumns(dfValues):
n, m = dfValues.shape
s0, s1 = dfValues.strides
columnMajor = s0 < s1
toKeep = np.full(m, False, dtype=np.bool_)
# Find the columns to keep
# Only-optimized for column-major dataframes (quite complex otherwise)
for colId in nb.prange(m):
for rowId in range(n):
if dfValues[rowId, colId] != 0:
toKeep[colId] = True
break
# Optimization: no columns are discarded
if np.all(toKeep):
return dfValues
# Create a new dataframe
newColCount = np.sum(toKeep)
res = np.empty((n,newColCount), dtype=dfValues.dtype)
if columnMajor:
newColId = 0
for colId in nb.prange(m):
if toKeep[colId]:
for rowId in range(n):
res[rowId, newColId] = dfValues[rowId, colId]
newColId = 1
else:
for rowId in nb.prange(n):
newColId = 0
for colId in range(m):
res[rowId, newColId] = dfValues[rowId, colId]
newColId = toKeep[colId]
return res
result = pd.DataFrame(filterNullColumns(df.values))
這是我的 6 核機器上的結果:
Reference: 1094 ms
Valdi_Bo answer: 1262 ms
This implementation: 0.056 ms (300 ms with discarded columns)
在提供的示例(沒有丟棄的列)上,該實作比參考實作快約20 000 倍,在更多病理情況下(僅丟棄一列)快 4.2 倍。
如果您想達到更快的性能,那么您可以就地執行計算(危險,特別是由于 Pandas)或使用較小的資料型別(如np.uint8或np.int16),因為計算主要受記憶體限制。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/366367.html
上一篇:PandasDateTime索引,基于時間和日期過濾器為列賦值
下一篇:如何在熊貓中使用lamda和if