| 標識A | 纈氨酸A |
|---|---|
| 22 | 17.1 |
| 4 | 16.0 |
| 7 | 16.5 |
| 標識B | 瓦爾-B |
|---|---|
| 9 | 15.5 |
| 2 | 19.5 |
| 45 | 17.5 |
這些表(Excel 中的 4 列)是我的輸入(這里簡化為一個最小的作業示例)。Val-A 列中值的順序(此處:最大、最小、中間)是 Val-B 應排序的順序。也就是說,第二個表應該如下所示:
| 標識B | 瓦爾-B |
|---|---|
| 2 | 19.5 |
| 9 | 15.5 |
| 45 | 17.5 |
輸入列 Val-A 和 Val-B 中的值以及 ID-A 和 ID-B 中的 ID 的順序是任意的。同樣重要的是要注意 Val-A 和 Val-B 中的值永遠不會相等,即 Val-A 中的值都不是 Val-B 中的值。
如何在 Excel 中實作這一目標?
uj5u.com熱心網友回復:
我建議您對第一個表中的值進行排名,然后將第二個表中的排名與這些排名進行匹配以獲得所需的排序順序。
使用范圍:
=SORTBY(D2:E4,XLOOKUP(RANK(E2:E4,E2:E4),RANK(B2:B4,B2:B4),SEQUENCE(3)))
或使用結構化參考:
=SORTBY(Table2,XLOOKUP(RANK(Table2[Val-B],Table2[Val-B]),RANK(Table1[Val-A],Table1[Val-A]),SEQUENCE(ROWS(Table2))))

編輯
第二個表的行數多于第一個的情況。
在這方面有點拖延時間,因此沒有完全檢查。我無法讓 Rank 與 filter 一起作業,盡管檔案建議它應該可以作業,但它可以與 index.html 一起使用。為了避免大量重復,我把它放在一個 Let 陳述句中,如下所示:
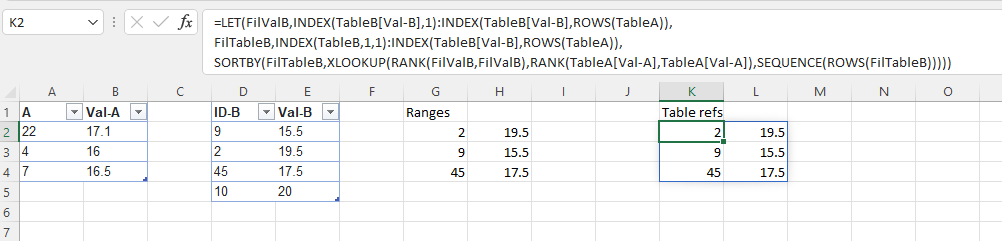
=LET(FilValB,INDEX(TableB[Val-B],1):INDEX(TableB[Val-B],ROWS(TableA)),
FilTableB,INDEX(TableB,1,1):INDEX(TableB[Val-B],ROWS(TableA)),
SORTBY(FilTableB,XLOOKUP(RANK(FilValB,FilValB),RANK(TableA[Val-A],TableA[Val-A]),SEQUENCE(ROWS(FilTableB)))))
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/367248.html
上一篇:Excel計算今天列中的特定數字