讓我們假設有以下 BigQuery 資料庫:
| 資產編號 | 緯度 | 經度 | 旅行狀態 | 時間戳 |
|---|---|---|---|---|
| 2 | 52.1052016 | 10.141829999999999 | 錯誤的 | 1638274080 |
| 2 | 52.10512 | 10.1420266 | 錯誤的 | 1638274081 |
| 2 | 52.104774899999995 | 10.1427066 | 真的 | 1638274085 |
| 2 | 52.1044833 | 10.1431966 | 真的 | 1638274088 |
| 2 | 52.104156599999996 | 10.143821599999999 | 真的 | 1638274092 |
| 2 | 52.10398 | 10.1441433 | 真的 | 1638274094 |
| 2 | 52.1038016 | 10.1444783 | 真的 | 1638274096 |
| 2 | 52.1036183 | 10.144823299999999 | 真的 | 1638274098 |
| 2 | 52.1034333 | 10.1451783 | 真的 | 1638274100 |
| 2 | 52.1032483 | 10.1455383 | 錯誤的 | 1638274102 |
| 2 | 52.1030533 | 10.145886599999999 | 真的 | 1638274104 |
| 2 | 52.1028666 | 10.146175 | 真的 | 1638274106 |
| 2 | 52.10279 | 10.1463266 | 真的 | 1638274108 |
| 2 | 52.1026616 | 10.1466566 | 真的 | 1638274110 |
| 2 | 52.102464999999995 | 10.147016599999999 | 真的 | 1638274112 |
| 2 | 52.102215 | 10.1474083 | 真的 | 1638274114 |
| 2 | 52.101968299999996 | 10.147795 | 真的 | 1638274116 |
| 2 | 52.101756599999995 | 10.148195 | 錯誤的 | 1638274117 |
| 2 | 52.101538299999994 | 10.14864 | 錯誤的 | 1638274119 |
| 2 | 52.1013583 | 10.149076599999999 | 錯誤的 | 1638274121 |
在提供的資料中有一個標志 - trip_status,指示在trip模式期間是否已捕獲給定坐標。
trip_status值從false變為true表示行程開始。trip_status值從true變為false表示行程結束。- 所有連續的行
trip_status = true都是屬于同一行程的行
題:
BigQuery 有沒有辦法從這樣的資料集中提取單獨的行程?也許以某種方式將trip_status標志所在的資料分組true并作為單獨的資料集回傳?
例如,從給定的資料中,我需要檢索如下內容:
行程一:
| 資產編號 | 緯度 | 經度 | 旅行狀態 | 時間戳 |
|---|---|---|---|---|
| 2 | 52.104774899999995 | 10.1427066 | 真的 | 1638274085 |
| 2 | 52.1044833 | 10.1431966 | 真的 | 1638274088 |
| 2 | 52.104156599999996 | 10.143821599999999 | 真的 | 1638274092 |
| 2 | 52.10398 | 10.1441433 | 真的 | 1638274094 |
| 2 | 52.1038016 | 10.1444783 | 真的 | 1638274096 |
| 2 | 52.1036183 | 10.144823299999999 | 真的 | 1638274098 |
| 2 | 52.1034333 | 10.1451783 | 真的 | 1638274100 |
行程二:
| 資產編號 | 緯度 | 經度 | 旅行狀態 | 時間戳 |
|---|---|---|---|---|
| 2 | 52.1030533 | 10.145886599999999 | 真的 | 1638274104 |
| 2 | 52.1028666 | 10.146175 | 真的 | 1638274106 |
| 2 | 52.10279 | 10.1463266 | 真的 | 1638274108 |
| 2 | 52.1026616 | 10.1466566 | 真的 | 1638274110 |
| 2 | 52.102464999999995 | 10.147016599999999 | 真的 | 1638274112 |
| 2 | 52.102215 | 10.1474083 | 真的 | 1638274114 |
| 2 | 52.101968299999996 | 10.147795 | 真的 | 1638274116 |
或者,甚至更好,例如:
| 排 | 資產編號 | 原點緯度 | 原點.經度 | 目的地.緯度 | 目的地.經度 | 折線 | 開始時間戳 | 結束時間戳 |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 52.104774899999995 | 10.1427066 | 52.1034333 | 10.1451783 | 來自所有行程坐標的 ST_MAKELINE | 1638274085 | 1638274100 |
| 1 | 2 | 52.1030533 | 10.145886599999999 | 52.101968299999996 | 10.147795 | 來自所有行程坐標的 ST_MAKELINE | 1638274104 | 1638274116 |
uj5u.com熱心網友回復:
考慮以下方法
select id, trip_number,
array_agg(struct(latitude as origin_latitude, longitude as origin_longitude) order by timestamp limit 1)[offset(0)].*,
array_agg(struct(latitude as destination_latitude, longitude as destination_longitude) order by timestamp desc limit 1)[offset(0)].*,
st_makeline(array_agg(st_geogpoint(longitude, latitude) order by timestamp)) as polyline,
min(timestamp) as start_timestamp,
max(timestamp) as end_timestamp,
from (
select * except(trip_status, prev_status, next_status),
countif(trip_start_end = 'trip_start') over win trip_number
from (
select *,
case
when trip_status and not prev_status then 'trip_start'
when trip_status and not next_status then 'trip_end'
else ''
end trip_start_end
from (
select *,
ifnull(lag(trip_status) over win, false) prev_status,
ifnull(lead(trip_status) over win, false) next_status
from your_table
window win as (partition by id order by timestamp)
)
)
where trip_status
window win as (partition by id order by timestamp)
)
group by id, trip_number
如果應用于您的問題中的樣本資料 - 輸出是

并在地理可視化中顯示
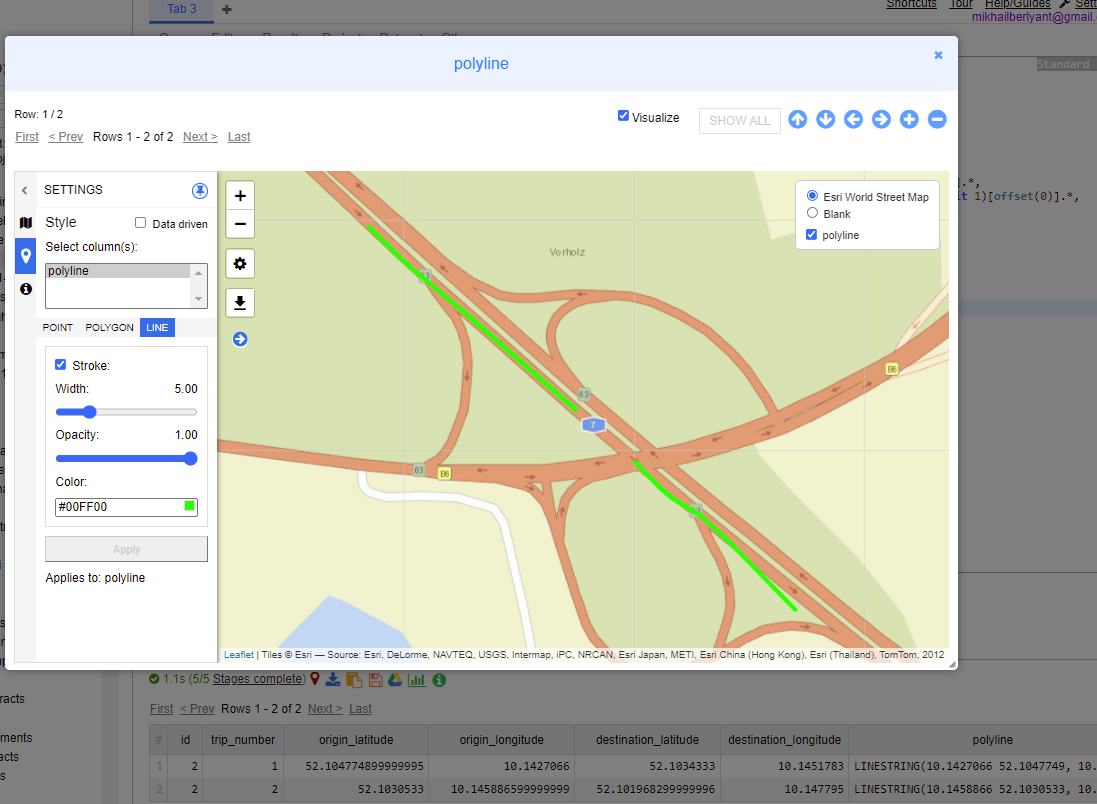
uj5u.com熱心網友回復:
需要考慮的重要一點是,您必須根據時間戳顯式地對資料進行排序。因為如果您只是從 BQ 的表中選擇資料,它會給您隨機行。因此,萬一(例如您的),請始終執行order by timestamp.
這是解決此問題的方法。首先,trip_status從有序資料集 ( lag) 中找出每一行的前 一個。然后使用之前的行程和當前的行程狀態(基于您的邏輯)來確定行程的起點和終點。然后使用這些行對介于兩者之間的值進行分組。
with formatted as (
select
asset_id,
lat,
lon,
ts,
trip_status,
first_value(flag) over (partition BY grp order by ts) as trip_id,
st_geogpoint(lat, lon) as geo_point
from (
select
asset_id,
lat,
lon,
ts,
trip_status,
flag,
sum(case when flag is null then 0 else 1 end) over (order by ts) as grp
from (
select
asset_id,
lat,
lon,
trip_status,
case
when previous_trip_status = false and current_trip_status = true then concat('START', '->', cast(ts AS string))
when previous_trip_status = true and current_trip_status = false then concat('END', '->', cast(ts AS string))
end as flag,
ts
from (
select
asset_id,
lat,
lon,
trip_status,
timestamp,
lag(trip_status) over (order by 1=1) as previous_trip_status,
trip_status as current_trip_status,
timestamp AS ts
from `mydataset.mytable`
)
)
)
where trip_status = true
)
select
asset_id,
trip_id,
array_agg(geo_point)[safe_offset(0)] as origin,
array_reverse(array_agg(geo_point))[safe_offset(0)] as destination,
ST_MAKELINE(array_agg(geo_point order by ts)) as polyline ,
min(ts) as start_timestamp,
max(ts) as end_timestamp
from formatted
group by 1,2
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/370189.html