我有兩個與此長度相同的一維陣列:
import numpy as np
a = np.array([1, 1, 1, 2, 2, 3, 4, 5])
b = np.array([7, 7, 8, 8, 9, 8, 10, 10])
的值在a增加的同時b是隨機的。
我想按照以下步驟按它們的值配對它們:
選取
[1]陣列的第一個唯一值 ( )a并獲取[7, 8]陣列b在同一索引處的唯一編號 ( ) 。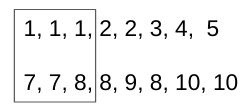
如果某些成對的數字 (
[8]) 再次出現在 中b,則在 的相同索引處選擇數字a。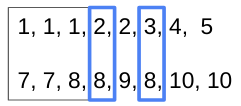
然后,
[2]再次出現在 中的一些新的配對數字(),在相同索引處的a數字b被選中。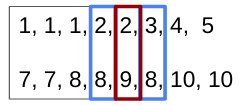
最后,結果應該是:
[1, 2, 3] is paired with [7, 8, 9]
[4, 5] is paired with [10]
uj5u.com熱心網友回復:
我嘗試通過同時迭代兩個陣列并跟蹤哪個元素與結果的哪個索引相關聯來做到這一點。讓我知道這對你有用嗎?
a = [1, 1, 1, 2, 2, 3, 4, 5]
b = [7, 7, 8, 8, 9, 8, 10, 10]
tracker_a = dict()
tracker_b = dict()
result = []
index = 0
for elem_a, elem_b in zip(a, b):
if elem_a in tracker_a:
result[tracker_a[elem_a]][1].add(elem_b)
tracker_b[elem_b] = tracker_a[elem_a]
elif elem_b in tracker_b:
result[tracker_b[elem_b]][0].add(elem_a)
tracker_a[elem_a] = tracker_b[elem_b]
else:
tracker_a[elem_a] = index
tracker_b[elem_b] = index
result.append([{elem_a}, {elem_b}])
index = 1
print(result)
輸出:
[[{1, 2, 3}, {8, 9, 7}], [{4, 5}, {10}]]
復雜度:O(n)
uj5u.com熱心網友回復:
看起來矢量化(無回圈)解決方案沒有簡單的方法,因為它是尋找連通分量的圖論問題。如果您仍然想要一個在大資料上快速運行的高性能腳本,您可以使用igraph用 C 撰寫的庫。
TL; 博士
我假設您的輸入對應于某個圖的邊:
>>> np.transpose([a, b])
array([[ 1, 7],
[ 1, 7],
[ 1, 8],
[ 2, 8],
[ 2, 9],
[ 3, 8],
[ 4, 10],
[ 5, 10]])
所以你的頂點是:
>>> np.unique(np.transpose([a, b]))
array([ 1, 2, 3, 4, 5, 7, 8, 9, 10])
而且您會很高興(至少在開始時)認識社區,例如:
tags = np.transpose([a, b, communities])
>>> tags
array([[ 1, 7, 0],
[ 1, 7, 0],
[ 1, 8, 0],
[ 2, 8, 0],
[ 2, 9, 0],
[ 3, 8, 0],
[ 4, 10, 1],
[ 5, 10, 1]])
以便您將頂點(1, 2, 3, 7, 8, 9)包含在社區編號中,0并將頂點(4, 5, 10)包含在社區編號中1。
不幸的是,igraph不支持標記從 1 到 10 的圖節點或標簽中的任何 id 間隙。它必須從 0 開始并且 id 沒有間隙。所以你需要存盤初始索引,然后重新標記頂點,這樣邊是:
vertices_old, inv = np.unique(np.transpose([a,b]), return_inverse=True)
edges_new = inv.reshape(-1, 2)
>>> vertices_old
array([ 1, 2, 3, 4, 5, 7, 8, 9, 10]) #new ones are: [0, 1, 2, ..., 8]
>>> edges_new
array([[0, 5],
[0, 5],
[0, 6],
[1, 6],
[1, 7],
[2, 6],
[3, 8],
[4, 8]], dtype=int64)
下一步是使用igraph( pip install python-igraph)查找社區。您可以運行以下命令:
import igraph as ig
graph = ig.Graph(edges = edges_new)
communities = graph.clusters().membership #type: list
communities = np.array(communities)
>>> communities
array([0, 0, 0, 1, 1, 0, 0, 0, 1]) #tags of nodes [1 2 3 4 5 7 8 9 10]
然后檢索源頂點的標簽(以及目標頂點的標簽):
>>> communities = communities[edges_new[:, 0]] #or [:, 1]
array([0, 0, 0, 0, 0, 0, 1, 1])
找到后communities,解決方案的第二部分似乎是一個典型的 groupby 問題。你可以在pandas:
import pandas as pd
def get_part(source, communities):
part_edges = np.transpose([source, communities])
part_idx = pd.DataFrame(part_edges).groupby([1]).indices.values() #might contain duplicated source values
part = [np.unique(source[idx]) for idx in part1_idx]
return part
>>> get_part(a, communities), get_part(b, communities)
([array([1, 2, 3]), array([4, 5])], [array([7, 8, 9]), array([10])])
最終代碼
import igraph as ig
import numpy as np
import pandas as pd
def get_part(source, communities):
'''find set of nodes for each community'''
part_edges = np.transpose([source, communities])
part_idx = pd.DataFrame(part_edges).groupby([1]).indices.values() #might contain duplicated source values
part = [np.unique(source[idx]) for idx in part1_idx]
return part
a = np.array([1, 1, 1, 2, 2, 3, 4, 5])
b = np.array([7, 7, 8, 8, 9, 8, 10, 10])
vertices_old, inv = np.unique(np.transpose([a,b]), return_inverse=True)
edges_new = inv.reshape(-1, 2)
graph = ig.Graph(edges = edges_new)
communities = np.array(graph.clusters().membership)
communities = communities[edges_new[:,0]] #or communities[edges_new[:,1]]
>>> get_part(a, communities), get_part(b, communities)
([array([1, 2, 3]), array([4, 5])], [array([7, 8, 9]), array([10])])
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/370326.html