我想在python中撰寫一個名為compute(a,b,p,n)的函式,其中a,b,n是整數,n>0,p是素數,輸出元組(x,y)(x,y是整數)使得
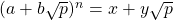
請注意,問題的限制條件是您不得使用任何外部庫。
現在,我著手通過撰寫一個遞回函式來解決這個問題。為此,讓我們假設
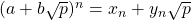
但是,我們也有
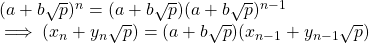
因此,我們有
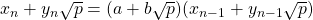
等式系數現在產生
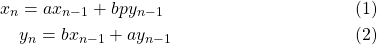
和
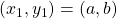
現在,利用(1)和(2)中的方程,我們可以撰寫一個簡單直接的遞回python函式作為
def compute(a,b,p,n):
if n==1:
return (a,b)
if n>1:
return (a*compute(a,b,p,n-1)[0] b*p*compute(a,b,p,n-1)[1], b*compute(a,b,p,n-1)[0] a*compute(a,b,p,n-1)[1])
這段代碼適用于較小的 n 值,比如高達 10,但對于較大的 n 值,它的效率非常低。是否有一些替代方法可以更快地解決此問題,或者可能有某種方法來優化此代碼以使其運行得更快?
uj5u.com熱心網友回復:
將基數 B 提高到 n次方的一個很好的遞回解決方案是利用恒等式 B n = (B 2 ) n/2表示 n 偶數,或 B*(B 2 ) n/2表示 n 奇數。這導致演算法具有 O(log n) 計算復雜度,對較大的 n 值產生顯著改進。對于您的特定問題,B = (a b*sqrt(p))。B 2計算為 (a 2 b 2 *p 2ab*sqrt(p)),而乘以 (a b*sqrt(p))(c d*sqrt(p)) 產生 ((ac bdp) (ad bc)sqrt(p))。將這些結果用于上述 n 偶數和 n 奇數情況會導致在 python 中實作以下實作:
def compute(a,b,p,n):
if n == 1: return (a,b)
c, d = compute(a*a b*b*p, 2*a*b, p, n // 2)
if n % 2 == 0:
return (c, d)
else:
return (a*c b*d*p, a*d b*c)
在實作這一點時,我注意到您的基本情況不正確。問題規范指出n嚴格大于0,所以基本情況應該是(a,b)對于n == 1因為(A B * SQRT(P))1 =(A B * SQRT(P))。如果您想包括零作為可能的冪,它將變為(1,0)for n == 0。您可以通過對代碼進行更改并將結果與?? 的手動計算進行比較來確認這是正確的compute(1, 2, 9, 2),即 (1 2sqrt(9)) 2 = 49的簡單平方應該是 (37 4sqrt(9 )) = 49。您的代碼當前產生 (19 3sqrt(9)) = 28 但在如上更正基本情況時會產生正確的答案。
相對于遞回,這種分而治之的方法的另一個優點是它可以處理非常大的 n 值而不會出現堆疊溢位。
uj5u.com熱心網友回復:
第一種優化可能性是compute(a,b,p,n-1)每次遞回呼叫僅運行一次。那么你會有
def compute(a,b,p,n):
if n==1:
return (1,1)
if n>1:
recursive_compute = compute(a,b,p,n-1)
return (a*recursive_compute[0] b*p*recursive_compute[1], b*recursive_compute[0] a*recursive_compute[1])
您可以做的第二件事是洗掉遞回并從 1 到 n 迭代,而不是從 n 到 1。python 中的遞回不是尾呼叫優化的,因此每次遞回呼叫后您的記憶體使用量都會增加。
這是一種方法
def compute(a,b,p,n):
current = (1,1)
for _ in range(n -1):
current = (a*current[0] b*p*current[1], b*current[0] a*current[1])
return current
由于我們不通過遞回增加堆疊并且不分配,這應該足夠快
uj5u.com熱心網友回復:
令人高興的是,你的方程是線性的:
x_n = a x_(n-1) b p x_(n-1)
y_n = b x_(n-1) a y_(n-1)
讓我們將這兩個標量方程重寫為單個矩陣向量方程:
X_n = M X_(n-1)
with:
X_n = (x_n) M = (a bp)
(y_n) (b a )
這個遞回方程給了我們一個直接方程 X_n 作為 n 的函式:
X_n = M^(n-1) X_1
其中的^意思是“矩陣求冪”。
現在,如果您可以訪問外部庫,則可以使用該庫的快速矩陣求冪函式。但既然你不這樣做,你就必須自己寫!
快速矩陣求冪與快速標量求冪基本相同:我們將使用這樣的事實,而不是乘以M自身的n次數,M^(2k) = (M^k)^2從而大幅減少矩陣乘法的次數。
我們最終得到以下代碼:
def matmul(A, B):
return [[sum(A[j][i] * B[k][j] for j in range(2)) for i in range(2)] for k in range(2)]
def matvecmul(M, X):
return [M[0][0]*X[0] M[0][1]*X[1], M[1][0]*X[0] M[1][1]*X[1]]
def matpow(M, n):
if n == 1:
return M
elif n % 2 == 0:
S = matpow(M, n//2)
return matmul(S, S)
else:
S = matpow(M, n//2)
return matmul(M, matmul(S, S))
def compute(a, b, p, n):
Mn = matpow([[a, b*p], [b, a]], n-1)
return matvecmul(Mn, [a,b])
測驗:
>>> from math import sqrt
>>> import timeit
>>> start = timeit.default_timer(); x,y = compute(sqrt(2)/2, sqrt(2)/2, -1, 100000); stop = timeit.default_timer()
>>> stop - start # execution time in seconds
0.00040509300015401095 # 0.4 millisecond
>>> x,y # should be (1, 0) because (sqrt(2)/2 * (1 sqrt(-1))) ** 100000 == exp(i pi/4)**(8*12500) == exp(i 2pi) == 1
(1.0000000000073506, 0.0)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/371656.html