問題
我在使用具有遞回資料結構的 Boost Serialization 庫時遇到問題。更準確地說,我想序列化一個矩陣,該矩陣由包含一個值的節點表示,并且每個節點都可以訪問其鄰居(頂部、底部、左側、右側)。為了訪問一個節點,每個入口點都存盤在一個vector(即每行和每列的第一個和最后一個節點)中。這是Node課程:
class Node
{
private:
int v;
Node* left;
Node* right;
Node* top;
Node* bottom;
public:
Node() : v(rand() % 100), left(NULL), right(NULL), top(NULL), bottom(NULL)
{
}
//Potential memory leak but that's not the topic
void setLeft(Node* toSet) { left = toSet; }
void setRight(Node* toSet) { right = toSet; }
void setTop(Node* toSet) { top = toSet; }
void setBottom(Node* toSet) { bottom = toSet; }
Node* gLeft() { return left; }
Node* gRight() { return right; }
Node* gTop() { return top; }
Node* gBottom() { return bottom; }
int gValue() { return v; }
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& v;
ar& left;
ar& right;
ar& top;
ar& bottom;
}
};
這是Matrix該類,帶有generateValues()此示例的函式:
class Matrix
{
private:
int m, n;
std::vector<Node*> firstNodesPerRow;
std::vector<Node*> lastNodesPerRow;
std::vector<Node*> firstNodesPerCol;
std::vector<Node*> lastNodesPerCol;
public:
Matrix(int m, int n) :
m(m), n(n),
firstNodesPerRow(m, NULL), lastNodesPerRow(m,NULL),
firstNodesPerCol(n, NULL),lastNodesPerCol(n, NULL)
{
}
void generateValues()
{
for (int i = 0; i < m; i )
{
for (int j = 0; j < n; j )
{
Node* toWrite = new Node();
if (i > 0)
{
toWrite->setTop(lastNodesPerCol.at(j));
lastNodesPerCol.at(j)->setBottom(toWrite);
lastNodesPerCol.at(j) = toWrite;
}
else
{
firstNodesPerCol.at(j) = toWrite;
lastNodesPerCol.at(j) = toWrite;
}
if (j > 0)
{
toWrite->setLeft(lastNodesPerRow.at(i));
lastNodesPerRow.at(i)->setRight(toWrite);
lastNodesPerRow.at(i) = toWrite;
}
else
{
firstNodesPerRow.at(i) = toWrite;
lastNodesPerRow.at(i) = toWrite;
}
}
}
}
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& m;
ar& n;
ar& firstNodesPerRow;
ar& firstNodesPerCol;
ar& lastNodesPerRow;
ar& lastNodesPerCol;
}
};
所以我想要實作的是序列化和反序列化一個Matrix. 這是我的main功能:
#include <cstdlib>
#include <sstream>
#include <vector>
#include <boost/archive/text_oarchive.hpp>
#include <boost/archive/text_iarchive.hpp>
#include <boost/serialization/vector.hpp>
int main(int argc, char* argv[])
{
int m = 10; int n = 10;
Matrix toSerialize(m,n);
toSerialize.generateValues();
/*
1) Serialize
*/
std::ostringstream oss;
boost::archive::text_oarchive oa(oss);
oa << toSerialize;
std::string serialiazedData = oss.str();
/*
2) Deserialize
*/
Matrix result(m,n);
std::stringstream serializedDataStream(serialiazedData);
boost::archive::text_iarchive ia(serializedDataStream);
ia >> result;
return EXIT_SUCCESS;
}
The problem is the following : given a sufficiently large value m or n, main ends up with a stack-overflow exception. I know that's it's coming from the serialize method of Node, because in order to serialize a node, it needs to serialize the neighbors and so on... I found 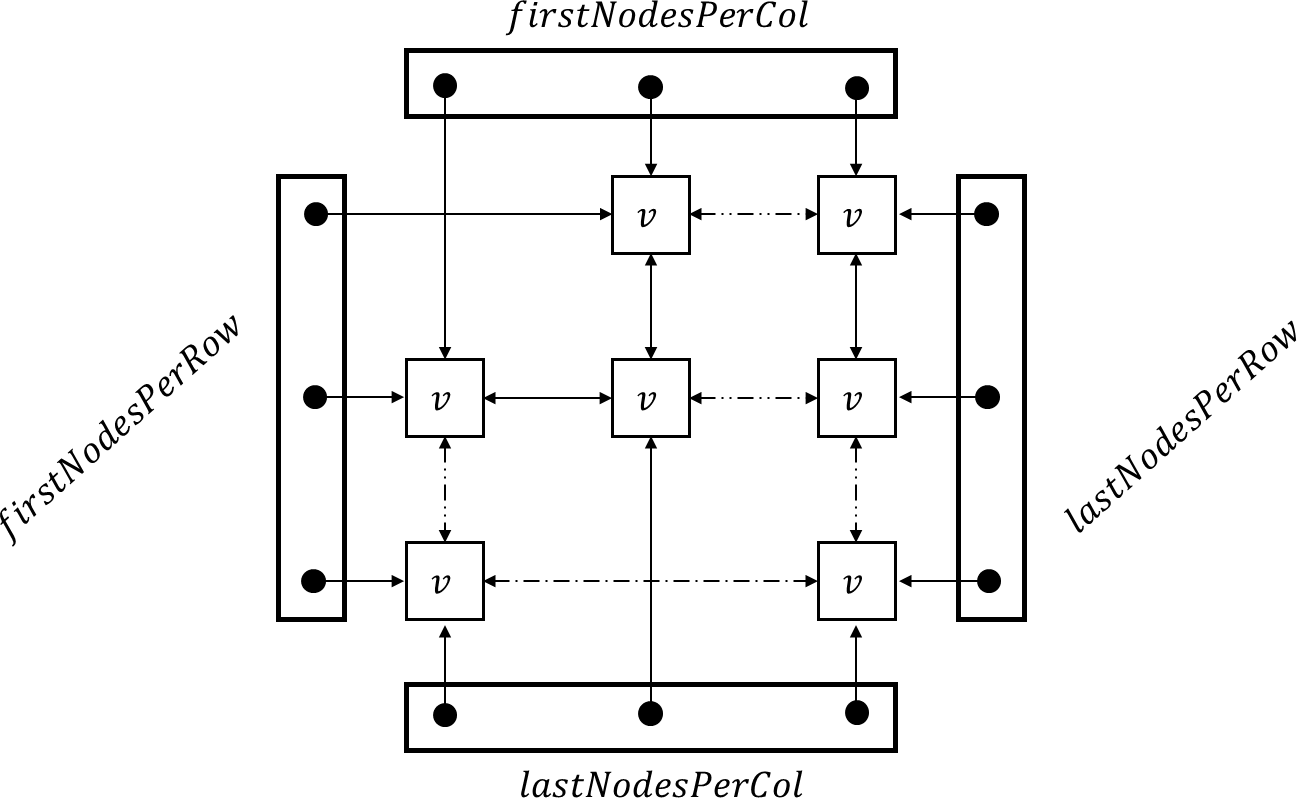
Edit 2 : The solution I had in mind (not working, ends up with a stack-overflow when deserializing).
//Class Node
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& v;
}
//Class Matrix
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& m;
ar& n;
for (int i = 0; i < m; i )
{
Node* current = firstNodesPerRow.at(i);
while (1)
{
if (current == NULL) { break; }
ar& current;
current = current->gRight();
}
}
ar& firstNodesPerRow;
ar& firstNodesPerCol;
ar& lastNodesPerRow;
ar& lastNodesPerCol;
}
Solution
The explanation of the solution is given in the post marked as the answer. Here is an implementation of this solution :
// class Node
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& v;
}
// some buffer struct
struct Neighbors
{
Node* top;
Node* bottom;
Node* left;
Node* right;
template <typename Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& top;
ar& bottom;
ar& left;
ar& right;
}
};
//class Matrix
template<class Archive>
void save(Archive& ar, const unsigned int version) const
{
std::map<Node*, Neighbors> neighborsPerNode;
for (int i = 0; i < m; i )
{
Node* current = firstNodesPerRow.at(i);
while (1)
{
if (current == NULL) { break; }
neighborsPerNode[current] = {
current->gTop(),
current->gBottom(),
current->gLeft(),
current->gRight(),
};
current = current->gRight();
}
}
ar& neighborsPerNode;
ar& m;
ar& n;
ar& firstNodesPerRow;
ar& firstNodesPerCol;
ar& lastNodesPerRow;
ar& lastNodesPerCol;
}
template<class Archive>
void load(Archive& ar, const unsigned int version)
{
// Warning ALL the nodes are browsed 2 times :
// 1 - to deserialize neighborsPerNode (below)
// 2 - in the for loop, to create the links between the nodes
std::map<Node*, Neighbors> neighborsPerNode;
ar& neighborsPerNode;
ar& m;
ar& n;
ar& firstNodesPerRow;
ar& firstNodesPerCol;
ar& lastNodesPerRow;
ar& lastNodesPerCol;
for (int i = 0; i < m; i )
{
Node* current = firstNodesPerRow.at(i);
while (1)
{
if (current == NULL) { break; }
Neighbors myNeighbors = neighborsPerNode.at(current);
current->setTop(myNeighbors.top);
current->setBottom(myNeighbors.bottom);
current->setLeft(myNeighbors.left);
current->setRight(myNeighbors.right);
current = current->gRight();
}
}
}
BOOST_SERIALIZATION_SPLIT_MEMBER()
uj5u.com熱心網友回復:
為什么不簡單地按矩陣的順序序列化所有元素并完全避免函式呼叫遞回,例如:
template<class Archive>
void serialize(Archive& ar, const unsigned int version)
{
ar& m;
ar& n;
for (int i = 0; i < m; i)
{
Node* node = firstNodesPerRow[i];
for (int j = 0; j < n; j)
{
ar & node->gValue();
node = node->gRight();
}
}
}
順便說一句,這適用于保存矩陣。我認為您需要在保存和加載版本中專門化序列化功能,因為對于加載版本,您需要:
- 負載 n, m
- 分配所有節點并在矩陣中填充節點指標向量
- 以與保存期間相同的順序加載所有值
template<class Archive>
void save(Archive & ar, const unsigned int version) const
{
...
}
template<class Archive>
void load(Archive & ar, const unsigned int version)
{
...
}
BOOST_SERIALIZATION_SPLIT_MEMBER()
在節點可能丟失的復雜情況下,同樣的想法也適用。而且您仍然需要在保存/加載之間進行拆分,為加載添加分配。但是需要更多的簿記才能正確保存和再次加載。
例如,您可以首先像上面一樣遍歷所有節點,但創建從每個節點指標值到唯一遞增 ID 編號的映射。當您保存每個節點的值(如上逐行)時,還要保存每個方向的節點 ID。加載時,首先制作一個空映射:ID -> 節點指標。然后逐行恢復節點,同時從地圖恢復鄰居指標。當然,無論何時第一次遇到 ID,您都需要分配一個新節點。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/371661.html
標籤:c recursion serialization boost stack-overflow
上一篇:如何遞回計算陣列中出現的次數
下一篇:跨多行刮一個句子|遞回錯誤未解決