下面是我的 .hdf5 檔案中資料分支的螢屏截圖。我試圖從這個特定的 BlinkStartEvent 段中提取現有的列名(即experiment_id、session_id....)。
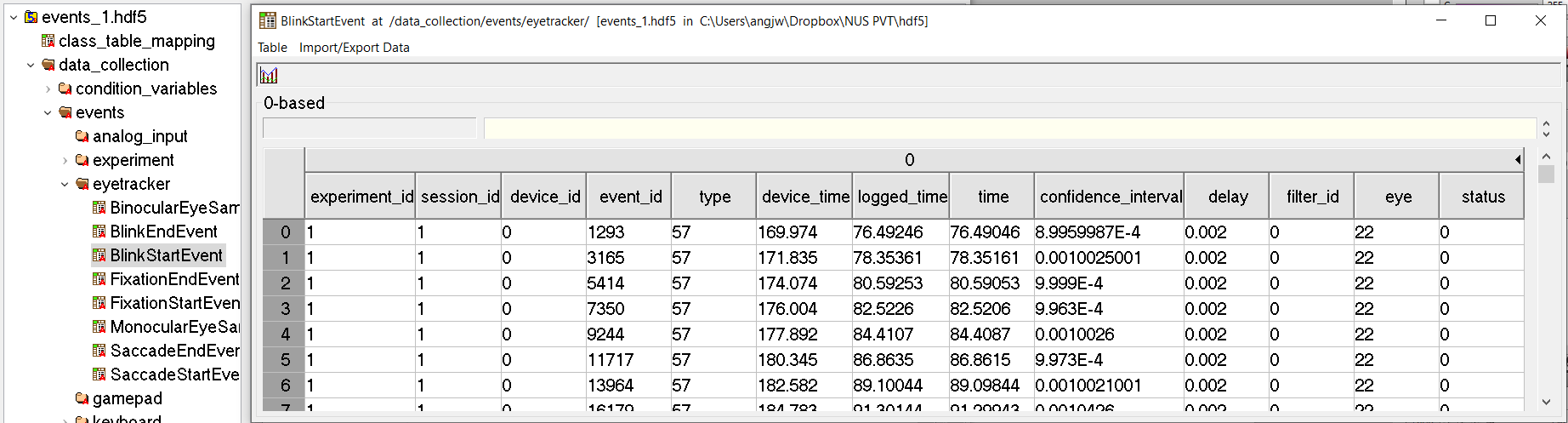
我有以下代碼可以訪問這部分資料并提取數字資料。但出于某種原因,我無法提取相應的列名,我希望將其附加到一個單獨的串列中,以便我可以從整個資料集創建一個字典。我以為 .keys() 應該這樣做,但它沒有。
import h5py
def traverse_datasets(hdf_file):
def h5py_dataset_iterator(g, prefix=''):
for key in g.keys():
#print(key)
item = g[key]
path = f'{prefix}/{key}'
if isinstance(item, h5py.Dataset): # test for dataset
yield (path, item)
elif isinstance(item, h5py.Group): # test for group (go down)
yield from h5py_dataset_iterator(item, path)
for path, _ in h5py_dataset_iterator(hdf_file):
yield path
with h5py.File(filenameHDF[0], 'r') as f:
for dset in traverse_datasets(f):
if str(dset[-15:]) == 'BlinkStartEvent':
print('-----Path:', dset) # path that leads to the data
print('-----Shape:', f[dset].shape) #the length dimension of the data
print('-----Data type:', f[dset].dtype) #prints out the unicode for all columns
data2 = f[dset][()] # The entire dataset
# print('Check column names', f[dset].keys()) # I tried this but I got a AttributeError: 'Dataset' object has no attribute 'keys' error
我得到以下輸出:
-----Path: /data_collection/events/eyetracker/BlinkStartEvent
-----Shape: (220,)
-----Data type: [('experiment_id', '<u4'), ('session_id', '<u4'), ('device_id', '<u2'), ('event_id', '<u4'), ('type', 'u1'), ('device_time', '<f4'), ('logged_time', '<f4'), ('time', '<f4'), ('confidence_interval', '<f4'), ('delay', '<f4'), ('filter_id', '<i2'), ('eye', 'u1'), ('status', 'u1')]
Traceback (most recent call last):
File "C:\Users\angjw\Dropbox\NUS PVT\Analysis\PVT analysis_hdf5access.py", line 64, in <module>
print('Check column names', f[dset].keys())
AttributeError: 'Dataset' object has no attribute 'keys'
我在這里出了什么問題?
另外,是否有一種更有效的方式來訪問資料,以便我可以做一些(假設的)類似的事情:
data2[0]['experiment_id'] = 1
data2[1]['time'] = 78.35161
data2[2]['logged_time'] = 80.59253
而不是必須經歷為每一行資料設定字典的程序?
uj5u.com熱心網友回復:
你很接近。資料集.dtype為您提供 NumPy dtype 的資料集。添加.descr將其作為(欄位名稱、欄位型別)元組串列回傳。請參閱下面的代碼以列印回圈中的欄位名稱:
for (f_name,f_type) in f[dset].dtype.descr:
print(f_name)
有比為每一行資料創建字典更好的方法來處理 HDF5 資料(除非您出于某種原因絕對需要字典)。h5py 旨在處理類似于 NumPy 陣列的資料集物件。(但是,并非所有 NumPy 操作都適用于 h5py 資料集物件)。以下代碼訪問資料并回傳 2 個相似(但略有不同)的資料物件。
# this returns a h5py dataset object that behaves like a NumPy array:
dset_obj = f[dset]
# this returns a NumPy array:
dset_arr = f[dset][()]
您可以使用標準 NumPy 切片符號(使用欄位名稱和行值)從任一物件中切片資料。從上面繼續...
# returns row 0 from field 'experiment_id'
val0 = dset_obj[0]['experiment_id']
# returns row 1 from field 'time'
val1 = dset_obj[1]['time']
# returns row 2 from field 'logged_time'
val2 = dset_obj[2]['logged_time']
(如果dset_obj用dset_arr上面替換,您將獲得相同的值。)
您還可以像這樣對整個欄位/列進行切片:
# returns field 'experiment_id' as a NumPy array
expr_arr = dset_obj['experiment_id']
# returns field 'time' as a NumPy array
time_arr = dset_obj['time']
# returns field 'logged_time' as a NumPy array
logtime_arr = dset_obj['logged_time']
那應該回答你最初的問題。如果沒有,請添加評論(或修改帖子),我會更新我的答案。
uj5u.com熱心網友回復:
我之前的答案使用了 h5py 包(與您的代碼相同的包)。我喜歡使用另一個 Python 包來處理 HDF5 資料:PyTables(又名表)。兩者非常相似,每個都有獨特的優勢。
- h5py嘗試將 HDF5 功能集盡可能地映射到 NumPy。此外,它使用 Python 字典語法來迭代物件名稱和值。因此,如果您熟悉 NumPy,則很容易學習。否則,您必須學習一些 NumPy 基礎知識(例如查詢 dtype)。同構資料作為 a 回傳
np.array,異構資料(如您的)作為 a 回傳np.recarray。 - PyTables在 HDF5 和 NumPy 之上構建了一個額外的抽象層。我喜歡的兩個獨特功能是:1)對節點(組或資料集)進行遞回迭代,因此不需要自定義資料集生成器,以及 2)使用“表”物件訪問異構資料,該物件具有比基本 NumPy recarray 更多的方法方法。(此外,它可以對表進行復雜的查詢,具有高級索引功能,而且速度很快!)
為了比較它們,我用 PyTables 重寫了您的 h5py 代碼,以便您可以“看到”差異。我在您的問題中包含了所有操作,并包含了我的 h5py 答案中的等效呼叫。需要注意的差異:
- 該
f.walk_nodes()方法是一種內置方法,可替換您的生成器。但是,它回傳一個物件(在本例中為 Table 物件),而不是 Table(資料集)名稱。因此,使用物件而不是名稱的代碼略有不同。 - 用于
Table.read()將資料加載到 NumPy(記錄)陣列中。不同的示例展示了如何將整個 Table 加載到陣列中,或加載參考欄位名稱的單個列。
代碼如下:
import tables as tb
with tb.File(filenameHDF[0], 'r') as f:
for tb_obj in f.walk_nodes('/','Table'):
if str(tb_obj.name[-15:]) == 'BlinkStartEvent':
print('-----Name:', tb_obj.name) # Table name without the path
print('-----Path:', tb_obj._v_pathname) # path that leads to the data
print('-----Shape:', tb_obj.shape) # the length dimension of the data
print('-----Data type:', tb_obj.dtype) # prints out the np.dtype for all column names/variable types
print('-----Field/Column names:', tb_obj.colnames) #prints out the names of all columns as a list
data2 = tb_obj.read() # The entire Table (dataset) into array data2
# returns field 'experiment_id' as a NumPy (record) array
expr_arr = tb_obj.read(field='experiment_id')
# returns field 'time' as a NumPy (record) array
time_arr = tb_obj.read(field='time')
# returns field 'logged_time' as a NumPy (record) array
logtime_arr = tb_obj.read(field='logged_time')
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/372456.html
上一篇:找到串列中平方的數字的總和
下一篇:Python串列資料過濾