我給定的字串是“Today_is_Monday”。如果我將 Huffman 的編碼演算法應用于這個字串。如果沒有編碼,字串的總大小是(15*8) = 120位。編碼后的大小是(10*8 15 49) = 144位。
據我所知,霍夫曼的演算法用于減小尺寸。但是為什么編碼后的大小比原來的多呢?
我所做的更多細節如下
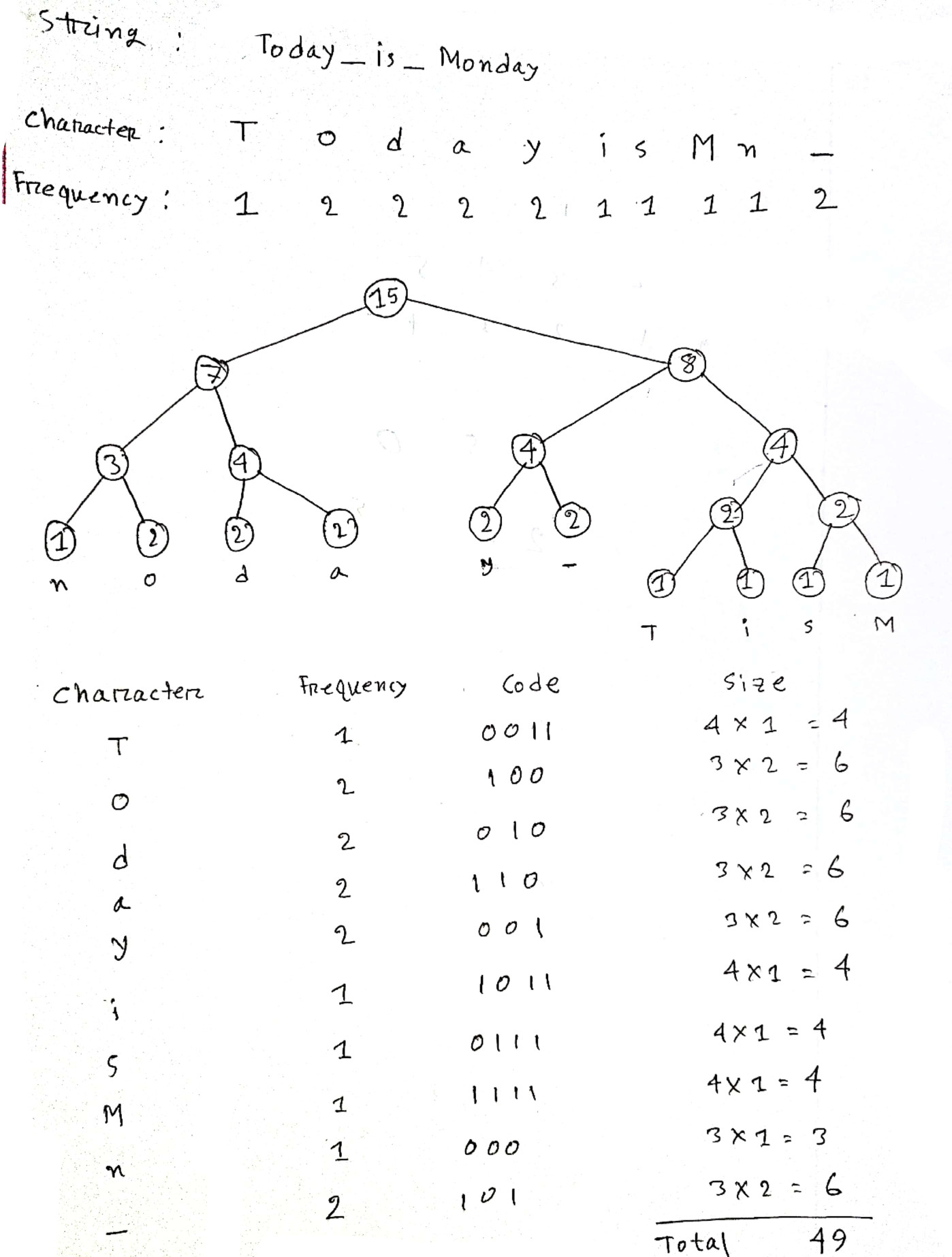
謝謝你。
uj5u.com熱心網友回復:
文本太短,概率分布函式看起來很均勻。如果出現頻率(或多或少)相同,則輸入字串將非常接近隨機噪聲。不可能以一般方式壓縮隨機噪聲,壓縮很可能比輸入序列更長,因為還需要添加一些元資料,例如編碼表。
相反,請考慮對以下字串進行編碼:aaaaaaaaaaaaaaa。
如果試圖對較長的一般英語文本進行編碼,人們會在某個時候注意到,編碼后的字串大小將開始變得比原始文本短得多。這是因為編碼的序列頻率將開始產生更大的影響 - 最頻繁的字符將使用盡可能短的代碼進行編碼,并且因為它重復很多次,其較短的大小將主導原始字符的大小。
uj5u.com熱心網友回復:
給定頻率表,霍夫曼編碼優化了訊息長度。您如何處理頻率表取決于您。
非常短訊息的應用程式通常假設發送器和接收器都事先知道一個靜態頻率表,因此不必傳輸它。
需要發送頻率表的應用程式通常會執行額外的優化。可以通過按字母順序僅傳輸每個符號的長度來傳達樹。然后可以對長度本身進行霍夫曼編碼。
uj5u.com熱心網友回復:
沒有可逆壓縮演算法可以保證壓縮所有可能的輸入。如果有,那么您可以反復為其提供自己的輸出,并最終將任何輸入檔案減少到 1 位。對于任何初始輸入檔案。
因此,必須有一些輸入不能被任何特定演算法壓縮。
正如其他人所解釋的那樣,您發現了霍夫曼無法壓縮的輸入。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/374279.html
上一篇:需要遞回解釋