我有一個40帶有奇怪名稱的傳感器的資料集(例如A_B_Loc_1)。我需要將這些資料轉換為長格式來繪制它們。我需要拆分名稱,以便我知道傳感器名稱(例如 from A_B_Loc_1, name=AB)和傳感器位置(例如 from A_B_Loc_1, location=1)。
require(dplyr)
require(janitor)
require(tidyfast)
require(tidyr)
df<-data.frame(time=c("2021-02-27 22:06:20","2021-02-27 23:06:20"),A_Loc_1=c(500,600),A_Loc_2=c(500,600),A_B_Loc_1=c(500,600),A_B_Loc_2=c(500,600),B_Loc_1=c(500,600),B_3=c(500,600))
大約有 5000 萬行,所以很慢:
編輯:哎喲!有些名稱沒有“Loc”(例如 B_3 是傳感器 B,位置 3)。
#旋轉它:
df %>%
tidyfast::dt_pivot_longer( #tidyfast package uses data.table instead of tidyr, so much faster
cols = -time,
names_to = "name",
values_to = "value"
) %>% drop_na()->df
#拆分名稱
df %>%
separate(name,
into = c("sensor", "location"),
sep = "(?=[0-9])"
) %>%
mutate(sensor=janitor::make_clean_names(sensor, case = "big_camel"))
這能加速嗎?一個left join與基于傳感器的名稱添加列的查詢表?
uj5u.com熱心網友回復:
我們嘗試了幾種通過正則運算式拆分列的方法。separate非常慢,但最快的似乎是stringr::str_split(..., simplify=TRUE)創建新列(用于小標題):
require(dplyr)
require(janitor)
require(tidyr)
require(stringr)
df <-
data.frame(
time = c("2021-02-27 22:06:20", "2021-02-27 23:06:20"),
A_Loc_1 = c(500, 600),
A_Loc_2 = c(500, 600),
A_B_Loc_1 = c(500, 600),
A_B_Loc_2 = c(500, 600),
B_Loc_1 = c(500, 600)
)
df1 <- df %>%
# Suggestion from above about cleaning names first?
clean_names(case = "big_camel") %>%
tidyfast::dt_pivot_longer(
cols = -Time,
names_to = "name",
values_to = "value") %>%
drop_na() %>%
as_tibble
df1[c("sensor", "location")] <-
str_split(df1$name, "Loc", simplify = TRUE)
這是假設您最大的時間消耗是分離柱部分!
編輯
至少有四種拆分方式,根據拆分的復雜程度,使用其他方法(例如data.table::tstrsplit)可能會更快,但其中一些方法需要在所有行中進行一致的“拆分”:
library(tidyverse)
library(data.table)
# a sample of 100,000 pivoted rows
n <- 1e5
df <- data.frame(condition = c(rep("ABLoc1", times = n),
rep("ABLoc2", times = n),
rep("ACLoc1", times = n),
rep("ACLoc2", times = n),
rep("AALoc4", times = n)))
(speeds <- bench::mark(
separate = {
df_sep <- df %>%
separate(condition,sep = "Loc", into = c("part1", "part2"), remove = FALSE)
},
dt = {
df_dt <- data.table::data.table(df)
df_dt <-
df_dt[, c("part1" , "part2") := tstrsplit(condition, split = "Loc", fixed = TRUE)]
},
stringr = {
df_str <- df
df_str[c("part1", "part2")] <- str_split(df_str$condition, "Loc", simplify = TRUE)
},
gsub = {
df_vec <- df
df_vec$part1 <- gsub("(^.*)Loc.*", "\\1", df$condition)
df_vec$part2 <- gsub(".*Loc(.*$)", "\\1", df$condition)
},
iterations = 10,
check = FALSE
))
#> # A tibble: 4 x 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 separate 4.63s 5.19s 0.191 3.89GB 4.25
#> 2 dt 99.44ms 112.32ms 8.95 28.91MB 0.895
#> 3 stringr 296.11ms 306.5ms 3.16 59.53MB 0.632
#> 4 gsub 502.85ms 528.69ms 1.63 7.63MB 0.163
plot(speeds, type = "beeswarm")
繪制每種方法的速度(迭代超過 100,000 行):
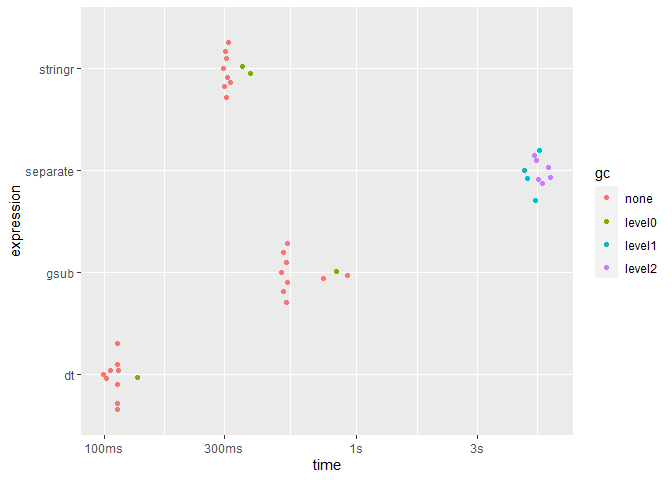
由reprex 包(v2.0.1)于 2021 年 12 月 8 日創建
uj5u.com熱心網友回復:
library(data.table)
setDT(df)
dt <- melt(df, id.vars = c("time"))
dt[, c("name", "location") := tstrsplit(str_replace_all(variable, "_", ""), "Loc")]
dt
# time variable value name location
# 1: 2021-02-27 22:06:20 A_Loc_1 500 A 1
# 2: 2021-02-27 23:06:20 A_Loc_1 600 A 1
# 3: 2021-02-27 22:06:20 A_Loc_2 500 A 2
# 4: 2021-02-27 23:06:20 A_Loc_2 600 A 2
# 5: 2021-02-27 22:06:20 A_B_Loc_1 500 AB 1
# 6: 2021-02-27 23:06:20 A_B_Loc_1 600 AB 1
# 7: 2021-02-27 22:06:20 A_B_Loc_2 500 AB 2
# 8: 2021-02-27 23:06:20 A_B_Loc_2 600 AB 2
# 9: 2021-02-27 22:06:20 B_Loc_1 500 B 1
# 10: 2021-02-27 23:06:20 B_Loc_1 600 B 1
編輯: OP 提到 Loc 并不總是存在,所以我們在最后一個下劃線處拆分以獲得數字。然后我們在第二步中清理名稱以洗掉下劃線和 - 如果存在 - “Loc”
dt <- melt(df, id.vars = c("time"))
dt[, c("name", "location") := tstrsplit(variable, "_(?!.*_)", perl = T)]
dt[, name := str_replace_all(name, "_|Loc", "")]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/376487.html
下一篇:完整的數字向量