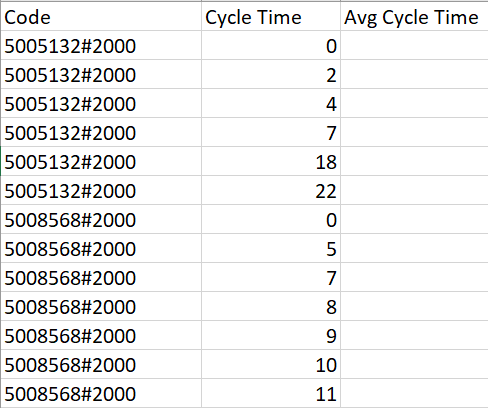
我有這樣的資料。代碼5005132#2000有6個條目,其中“0”為最小值,最大值為“22”;代碼5008568#2000有7個條目,其中“0”為最小值,“11”是最大值。我必須洗掉與特定代碼相關的這些最小值和最大值,并計算特定代碼的“平均值”。
5005132#2000 的平均值應為 7.75,5008568#2000 的平均值應為 7.8
uj5u.com熱心網友回復:
一種解決方案是使用data.table。data.table 就像一個 data.frame,但增加了功能。您首先需要加載 data.table 包并將 data.frame ( df) 轉換為 data.table
library(data.table)
setDT(df)
從那里,使用 過濾掉每個組的極端值by,然后獲得剩余值的平均值。
# Solution:
df[,
# ID rows where value is min/max
.(Cycle.Time, "drop" = Cycle.Time %in% range(Cycle.Time)), by=Code][
# Filter to those where value is not mon/max and get mean per Code
drop==FALSE, mean(Cycle.Time), by=Code]
另一種方法是使用 dplyr
df %>%
group_by(Code) %>%
filter(!Cycle.Time %in% range(Cycle.Time)) %>%
summarize(mean(Cycle.Time))
并將其存盤在 data.frame 中:
df %>%
group_by(Code) %>%
filter(!Cycle.Time %in% range(Cycle.Time)) %>%
summarize(mean(Cycle.Time)) %>%
data.frame -> averages
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/376496.html
標籤:r
上一篇:從df列R中提取特定文本部分
下一篇:基于向量復制一行(特定列)