我有以下資料幀:
from datetime import datetime as dt
import numpy as np
import pandas as pd
inputs = {
'indicator':[69.88, 85.05, 50.19, 71.08, 44.83, 36.32, 29.42, 44.47, 34.71, 37.91, 32.78, 35.85, 38.98, 23.16, 73.22, 77.77, 49.22, 59.1, 83.38, 88.5, 47.78],
'short_trade':[0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0],
'pnl':[-0.0, -0.0, 0.05, -0.06, 0.05, 0.0, 0.0, -0.0, 0.0, -0.0, 0.0, -0.0, -0.0, 0.0, -0.0, -0.0, 0.01, -0.0, -0.0, -0.01, 0.03]
}
_idx = pd.date_range('2018-08-10','2018-09-09',freq='D').to_series()
_idx = _idx[_idx.dt.dayofweek < 5]
data = pd.DataFrame(inputs, index = _idx)
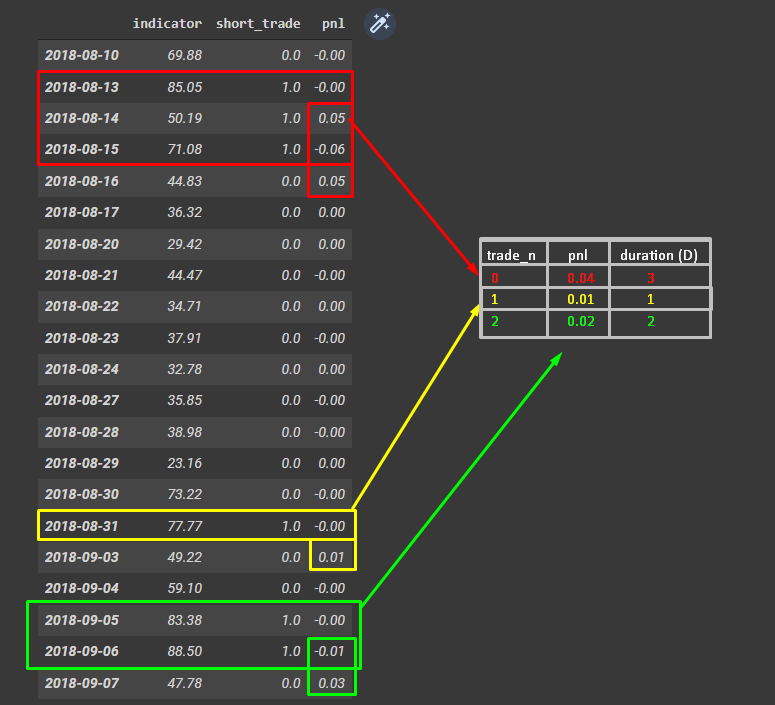
我的目標是創建一個新的 DataFrame,如下面的螢屏截圖所示。分組時間short_trade != 0或pnl != 0(這是同一件事)。
新 DataFrame ( trade_n)的第一列只是每個不同交易的 ID。新列pnl是來自初始 DataFrame 的每個組的總和。最后,duration (D)是每筆交易持續的天數。
我找到了一種解決方法,回圈遍歷 DataFrame 并檢查每一行,但我很確定使用 pandas/numpy 有更有效的解決方案。
uj5u.com熱心網友回復:
試試這個:
s = df \
.groupby((df['short_trade'].astype(bool) | df['short_trade'].shift(1)).diff().cumsum()) \
.apply(lambda x: [x.shape[0] - 1, x['pnl'].tolist()]) \
[::2] \
.reset_index(drop=True) \
.tolist()
df = pd.DataFrame(s, columns=['duration (D)', 'pnl']) \
.reset_index() \
.rename({'index': 'trade_n'}, axis=1)
輸出:
>>> df
trade_n duration (D) pnl
0 0 3 [-0.0, 0.05, -0.06, 0.05]
1 1 1 [-0.0, 0.01]
2 2 2 [-0.0, -0.01, 0.03]
uj5u.com熱心網友回復:
IUC:
m = df.short_trade.ne(0) | df.pnl.ne(0)
g = mask.eq(True) & mask.shift().eq(False)
out = df.assign(trade_n=g.cumsum().sub(1)[m]).groupby('trade_n') \
.agg(**{'pnl': ('pnl', lambda x: sum(x[x.ne(0)])),
'duration (D)': ('short_trade', lambda x: len(x.ne(0)))}) \
.reset_index().astype({'trade_n': int})
輸出:
>>> out
trade_n pnl duration (D)
0 0 0.04 4
1 1 0.01 2
2 2 0.02 3
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/386217.html
下一篇:熊貓檢查多列的條件并減去1