根據以下建議,我已將資料框合并為一個 DF。因此也更改了標題。以下是我的合并資料框的螢屏截圖:
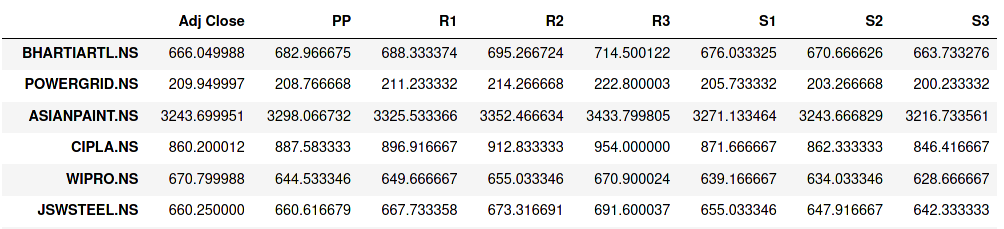
我現在需要將 Adj Close 與其他列進行比較,以準確了解它的位置 - 例如它在 PP 和 R1、R1 和 R2、R2 和 R3 之間等等。基于此,我需要創建一個新的狀態列,這將具有相關的狀態。我寫的功能如下
def check_status(merged):
if merged['Adj Close'] < merged['R3']:
merged['Status'] = 'Breached R3'
elif merged['R3'] < merged['Adj Close'] < merged['R2']:
merged['Status'] = 'Breached R2'
elif merged['R2'] < merged['Adj Close'] < merged['R1']:
merged['Status'] = 'Breached R1'
elif merged['R1'] < merged['Adj Close'] < merged['PP']:
merged['Status'] = 'Breached PP on lower side'
elif merged['PP'] < merged['Adj Close'] < merged['S1']:
merged['Status'] = 'Breached PP on higher side'
elif merged['S1'] < merged['Adj Close'] < merged['S2']:
merged['Status'] = 'Breached S1'
elif merged['S2'] < merged['Adj Close'] < merged['S3']:
merged['Status'] = 'Breached S2'
else:
merged['Status'] = 'Breached S3'
return merged
這給出了如下錯誤:
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
接下來我嘗試使用 np.where()。代碼片段如下:
merged['Status'] = np.where(merged['Adj Close'] < merged['R3'], 'Breached R3', merged['Adj Close'])
merged['Status'] = np.where(merged['R2'] < merged['Adj Close'] < merged['R1'], 'Breached R1', merged['Adj Close'])
merged['Status'] = np.where(merged['R1'] < merged['Adj Close'] < merged['PP'], 'Breached PP on lower side', merged['Adj Close'])
merged['Status'] = np.where(merged['PP'] < merged['Adj Close'] < merged['S1'], 'Breached PP on higher side', merged['Adj Close'])
merged['Status'] = np.where(merged['S1'] < merged['Adj Close'] < merged['S2'], 'Breached S1', merged['Adj Close'])
merged['Status'] = np.where(merged['S2'] < merged['Adj Close'] < merged['S3'], 'Breached S2', merged['Adj Close'])
merged['Status'] = np.where(merged['S3'] < merged['Adj Close'], 'Breached S3', merged['Adj Close'])
但是,我得到了同樣的錯誤。
我有什么選項可以使狀態列更新如上?
我有一個很大的 DF,所以性能可能是一個考慮因素。
uj5u.com熱心網友回復:
np.select與整個資料框一起使用。
conditions = [
df['Adj Close'] < df['R3'],
(df['R2'] < df['Adj Close']) & (df['Adj Close'] < df['R1']),
(df['R1'] < df['Adj Close']) & (df['Adj Close'] < df['PP']),
(df['PP'] < df['Adj Close']) & (df['Adj Close'] < df['S1']),
(df['S1'] < df['Adj Close']) & (df['Adj Close'] < df['S2']),
(df['S2'] < df['Adj Close']) & (df['Adj Close'] < df['S3']),
df['S3'] < df['Adj Close']
]
values = [
'Breached R3',
'Breached R1',
'Breached PP on lower side',
'Breached PP on higher side',
'Breached S1',
'Breached S2',
'Breached S3'
]
df['Status'] = np.select(conditions, values, df['Adj Close'])
這將顯著加快您的程式@Sachin
uj5u.com熱心網友回復:
我np.where()在for回圈中解決了這個問題:
for i in merged:
merged['Status'] = np.where(merged['Adj Close'] > merged['R3'], 'Breached R3', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['R3'] > merged['Adj Close'], merged['Adj Close'] > merged['R2']), 'Breached R2', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['R2'] > merged['Adj Close'], merged['Adj Close'] > merged['R1']), 'Breached R1', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['R1'] > merged['Adj Close'], merged['Adj Close'] > merged['PP']), 'Breached PP on higher side', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['PP'] > merged['Adj Close'], merged['Adj Close'] > merged['S1']), 'Breached PP onn lower side', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['S1'] > merged['Adj Close'], merged['Adj Close'] > merged['S2']), 'Breached S1', merged['Status'])
merged['Status'] = np.where(np.logical_and(merged['S2'] > merged['Adj Close'], merged['Adj Close'] > merged['S3']), 'Breached S2', merged['Status'])
merged['Status'] = np.where(merged['S3'] > merged['Adj Close'] , 'Breached S3', merged['Status'])
非常感謝所有的建議。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/386219.html
上一篇:熊貓檢查多列的條件并減去1