我一直在使用keras的預處理方法 keras.preprocessing.image_dataset_from_directory()
這是我的 x 和 y 訓練批次:
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
train_path,
label_mode = 'categorical', #it is used for multiclass classification. It is one hot encoded labels for each class
validation_split = 0.2, #percentage of dataset to be considered for validation
subset = "training", #this subset is used for training
seed = 1337, # seed is set so that same results are reproduced
image_size = img_size, # shape of input images
batch_size = batch_size, # This should match with model batch size
)
valid_ds = tf.keras.preprocessing.image_dataset_from_directory(
train_path,
label_mode ='categorical',
validation_split = 0.2,
subset = "validation", #this subset is used for validation
seed = 1337,
image_size = img_size,
batch_size = batch_size,
)
我想知道是否有辦法為每個班級收集相等的樣本量?
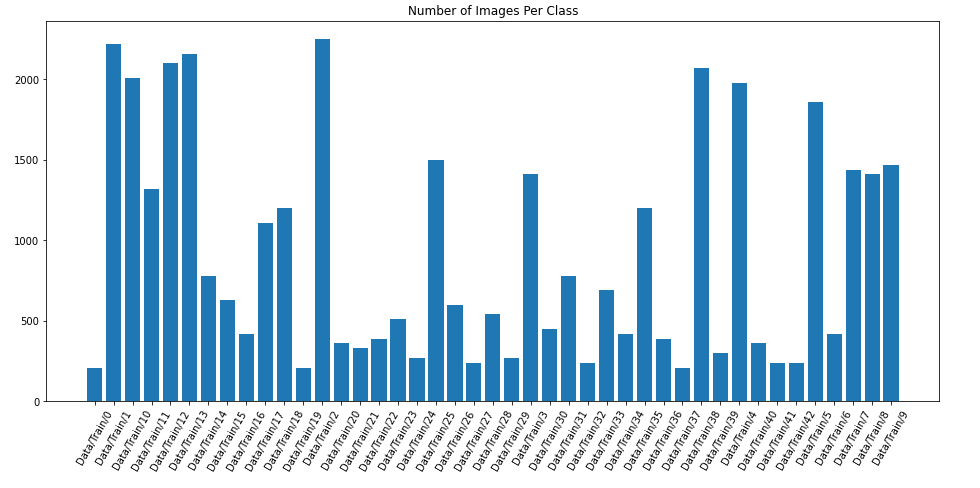
您可以在下面看到目標目錄中每個類的示例影像數量:
uj5u.com熱心網友回復:
回顧一下評論中的內容:問題出在不平衡的資料集上,在不采取任何措施的情況下在不平衡的資料集上訓練模型顯然會導致模型有偏差。
為了解決這個問題,Keras.fit()有一個名為class_weight. 我參考檔案中給出的描述:
class_weight:可選字典將類索引(整數)映射到權重(浮點數)值,用于對損失函式進行加權(僅在訓練期間)。這對于告訴模型“更多關注”來自代表性不足的類的樣本很有用。
現在要計算您的類權重,您可以使用此公式并手動計算每個類 j:
w_j= total_number_samples / (n_classes * n_samples_j)
例子:
A: 50
B: 100
C: 200
wa = 350/(3*50) = 2.3
wb = 350/(3*100) = 1.16
wc = 350/(3*200) = 0.58
或者你可以使用 scikit-learn:
#Import the function
from sklearn.utils import class_weight
# get class weights
class_weights = class_weight.compute_class_weight('balanced',
np.unique(y_train),
y_train)
# use the class weights for training
model.fit(X_train, y_train, class_weight=class_weights)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/392859.html