我有一個普通的資料框
import pandas as pd
d = {'id': [1,1,2,3,4,4,5], 'param': [11,22,33,44,55,66,77]}
df = pd.DataFrame(data=d)
我想創建一個新列并執行 cumsum 并在每隔一個 id 后重新開始一次,如下所示:
[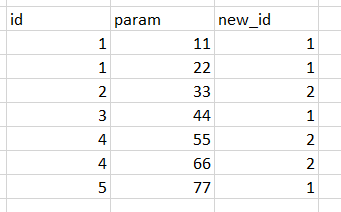
它從 1 開始。一旦 column1 ('id) 中有一個新值,它應該增加一。第 1 列中的新值再次應從 1 開始,依此類推。
uj5u.com熱心網友回復:
我認為您幾乎必須通過對資料進行分箱來解決這個問題。在這種情況下,我曾經qcut創建len(df) // 2垃圾箱 - 在這種情況下為 3。
如果查看結果,qcut您可以看到生成的組標簽:
pd.qcut(df.id,len(df)//2)
0 (0.999, 2.0]
1 (0.999, 2.0]
2 (0.999, 2.0]
3 (2.0, 4.0]
4 (2.0, 4.0]
5 (2.0, 4.0]
6 (4.0, 5.0]
使用 this 作為 groupby 鍵,我們可以檢查id每個組中的每個是否不等于id.shift,它回傳一個布林值,可用于cumsum
import pandas as pd
d = {'id': [1,1,2,3,4,4,5], 'param': [11,22,33,44,55,66,77]}
df = pd.DataFrame(data=d)
df['new_id'] = df.groupby(pd.qcut(df.id,len(df)//2)).apply(lambda x: (x.id.ne(x.id.shift())).cumsum()).values
輸出
id param new_id
0 1 11 1
1 1 22 1
2 2 33 2
3 3 44 1
4 4 55 2
5 4 66 2
6 5 77 1
uj5u.com熱心網友回復:
替代方法;似乎快了大約 3-4 倍。
2.2 ms ± 238 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
8.65 ms ± 884 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
df['new_id'] = df['id'].map(df.groupby('id').apply(lambda x: 1).cumsum().add(1).mod(2).add(1).to_dict())
id param new_id
0 1 11 1
1 1 22 1
2 2 33 2
3 3 44 1
4 4 55 2
5 4 66 2
6 5 77 1
uj5u.com熱心網友回復:
如果id列包含相鄰的整數(如示例中所示),您可以new_id通過查看 的最低有效位來匯出列id:
df["new_id"] = 2 - np.bitwise_and(1, df.id)
如果ids比較通用,可以先呼叫groupby ngroup,然后復用上面的方案:
df["new_id"] = np.bitwise_and(1, df.groupby(df.id).ngroup()) 1
結果:
id param new_id
0 1 11 1
1 1 22 1
2 2 33 2
3 3 44 1
4 4 55 2
5 4 66 2
6 5 77 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/397677.html
上一篇:如何創建和注釋堆積比例條形圖