我在資料幀 df 中有兩列 Col_A 和 Col_B。
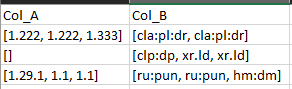
Col_A Col_B
[1.222, 1.222, 1.333] [cla:pl:dr, cla:pl:dr]
[] [clp:dp, xr.ld, xr.ld]
[1.29.1, 1.1, 1.1] [ru:pun, ru:pun, hm:dm]
我想洗掉 ea 中的重復值。ea 清單。Col_A 和 Col_B 的行,如下所示。
type(df['Col_A'][0]) 回報 list
我嘗試過的示例回傳不可散列的型別錯誤。我試圖避免此錯誤但無濟于事的方法包括:
df['Col_A'].map(lambda x: tuple(set(x)))
我怎么解決這個問題?
編輯:復制粘貼的資料。
uj5u.com熱心網友回復:
看起來您正在使用字串作為資料。
data = {'col_A': [['1.222', '1.222', '1.333'], [], ['1.29.1', '1.1', '1.1']] ,
'col_B': [['cla:pl:dr', 'cla:pl:dr'], ['clp:dp', 'xr.ld', 'xr.ld'], ['ru:pun', 'ru:pun', 'hm:dm']] }
df = pd.DataFrame(data)
df['col_A'] = df['col_A'].apply(lambda x: list(set(x)))
df['col_B'] = df['col_B'].apply(lambda x: list(set(x)))
輸出DF
col_A col_B
0 [1.222, 1.222, 1.333] [cla:pl:dr, cla:pl:dr]
1 [] [clp:dp, xr.ld, xr.ld]
2 [1.29.1, 1.1, 1.1] [ru:pun, ru:pun, hm:dm]
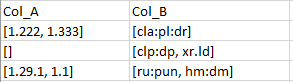
OutPut DF(洗掉重復項后)
col_A col_B
0 [1.222, 1.333] [cla:pl:dr]
1 [] [clp:dp, xr.ld]
2 [1.29.1, 1.1] [ru:pun, hm:dm]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/398305.html
上一篇:轉換json字典和串列
下一篇:隨著時間的推移創建累積串列