我正在嘗試使用REGEXEXTRACT谷歌表格中的公式從文本中提取所有帶有大寫首字母的單詞。
理想情況下,句子的第一個詞應該被忽略,并且只提取所有帶有第一個大寫字母的后續詞。
其他關閉問題和公式:
我發現了另外兩個問題和答案:
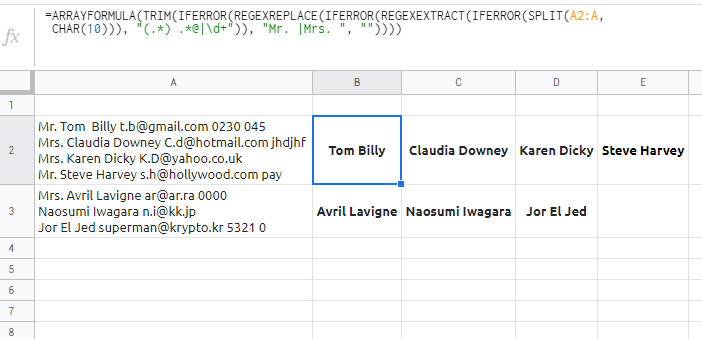 )
)
樣品表:
這是我的測驗
請參閱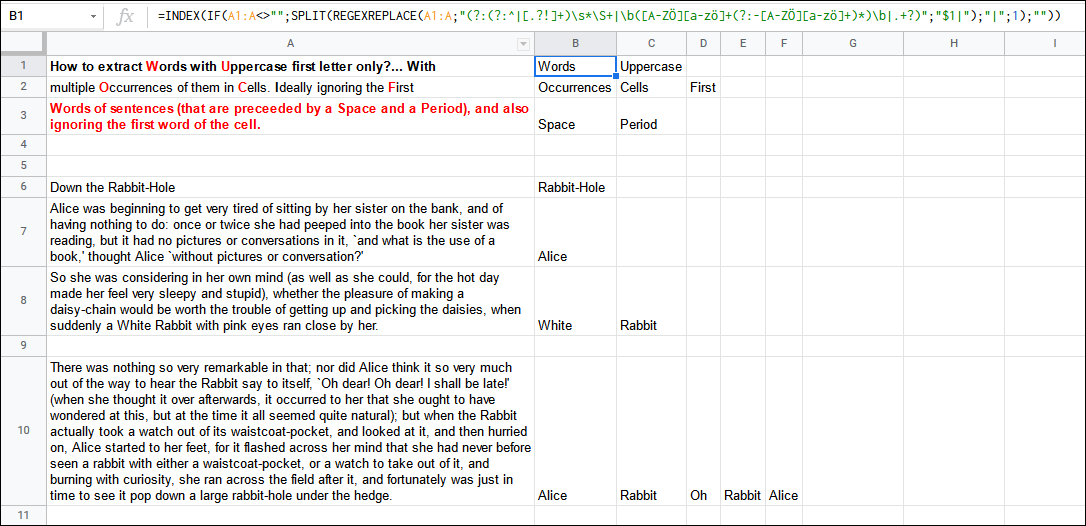
中的公式B1:
=INDEX(IF(A1:A<>"",SPLIT(REGEXREPLACE(A1:A,"(?:(?:^|[.?!] )\s*\S |\b([A-Z?][a-z?] (?:-[A-Z?][a-z?] )*)\b|. ?)","$1|"),"|",1),""))
圖案:(?:(?:^|[.?!] )\s*\S |\b([A-Z?][a-z?] (?:-[A-Z?][a-z?] )*)\b|. ?)表示:
(?:- 打開非捕獲組以允許交替:(?:^|[.?!] )\s*\S- 一個嵌套的非捕獲組,允許起始行錨點或1 個文字點或問號/感嘆號,后跟 0 個空白字符和 1 個非空白字符;|- 或者;\b([A-Z?][a-z?] (?:-[A-Z?][a-z?] )*)\b- 第一個捕獲組,用于捕獲單詞邊界之間的駝峰式字串(帶有可選連字符);|- 或者;. ?- 任何 1 個字符(懶惰);)- 關閉非捕獲組。
這里的想法是用于REGEXREPLACE()將任何匹配替換為對第一個捕獲組的反向參考和管道符號(或任何不會出現在您輸入中的符號),并用于SPLIT()分隔所有單詞。請注意,使用函式的第三個引數忽略空字串很重要。
INDEX()將觸發陣列功能并溢位結果。我使用嵌套IF()陳述句來檢查要跳過的空單元格。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/404772.html
標籤:
上一篇:谷歌表格中的查詢功能空輸出
下一篇:根據列對行求和?