我正在嘗試繪制以下李克特專案:
structure(list(`Likelihood of attending more frequently` = structure(c(4L,
4L, 4L, 3L, 4L, 4L, 3L, 4L, 5L, 4L, 4L, 4L, 4L, 5L, 3L, 5L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 1L, 4L, 5L, 4L, 3L, 2L, 3L,
3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 2L, 5L, 4L, 4L, 4L, 3L,
4L, 5L, 3L, 3L, 2L, 4L, 4L, 3L, 4L, 1L, 3L, 3L, 4L, 5L, 4L, 4L,
4L, 4L, 4L, 3L, 4L, 4L, 5L, 4L, 2L, 5L, 3L, 2L, 3L, 3L, 5L, 4L,
4L, 2L, 3L, 2L, 4L, 5L, 3L, 4L, 4L, 4L, 4L, 5L, 4L, 4L, 3L, 4L,
4L, 4L, 5L, 3L, 3L, 4L, 3L, 4L, 3L, 3L, 5L, 5L, 4L, 4L, 5L, 2L,
1L, 4L, 4L, 4L, 1L, 4L, 3L, 2L, 4L, 4L, 4L, 4L, 5L, 4L, 5L, 4L,
5L, 4L, 2L, 5L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 2L, 3L,
3L, 4L, 4L, 4L, 5L, 5L, 4L, 5L, 5L, 3L, 2L, 4L, 5L, 5L, 1L, 5L,
2L, 1L, 5L, 4L, 1L, 4L, 5L, 4L, 2L, 4L, 4L, 4L, 5L, 3L, 2L, 5L,
5L, 5L, 4L), .Label = c("Highly unlikely", "Somewhat unlikely",
"Neither likely nor unlikely", "Somewhat likely", "Highly likely"
), class = "factor"), Reason = structure(c(1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 7L, 7L, 7L, 7L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 6L, 6L, 6L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L), .Label = c("Class times conflict with my schedule",
"I am not interested in the content offered", "I don't have time",
"I don't have transportation", "I don't know where to find information on classes, programs, and events",
"Other", "There are not classes near me"), class = "factor")), row.names = c(NA,
-180L), class = "data.frame")
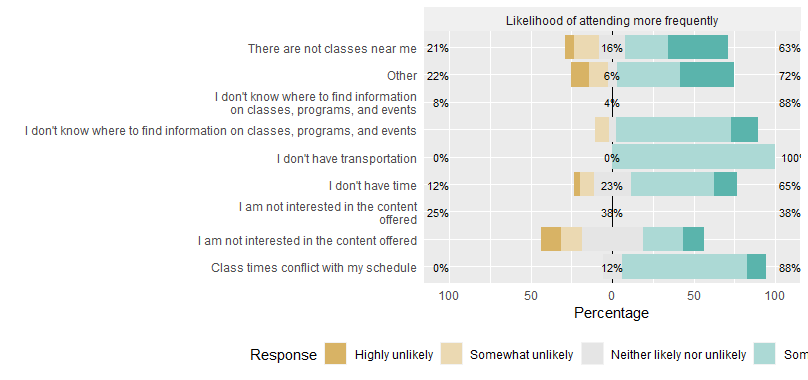
當我檢查 rhe 組專案的因子水平時,它顯示 7 但是,likert.bar.plot 有 9 個組,因為 2 個重復。
like<-likert(freq[, c(1), drop=FALSE], grouping = freq$Reason)
likert.bar.plot(like,wrap.grouping = 40)
我檢查了文本字串是否不同,但它們完全相同。知道是什么原因造成的嗎?
uj5u.com熱心網友回復:
正如我在評論中已經提到的那樣,這對我來說似乎是一個錯誤。從源代碼likert.bar.plot和影像來看,條形圖似乎使用了未包裝的組標簽,而百分比標簽使用了包裝的標簽。因此,我們最終得到了重復的組。
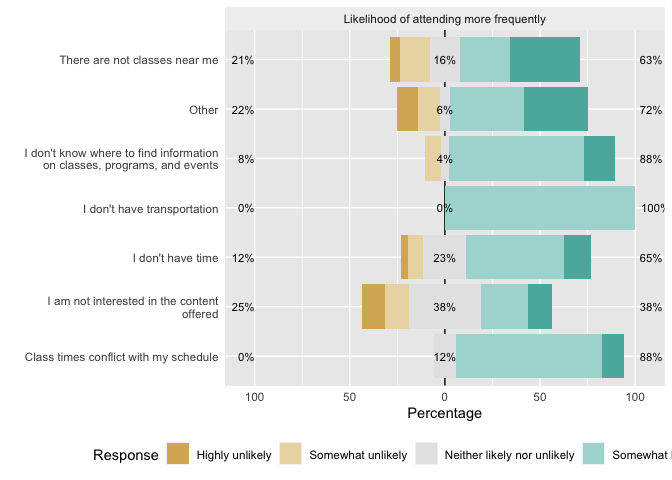
但是,作為一種解決方法,您可以在傳遞給 likert 之前手動包裝組標簽。要完成這項作業,您還必須為wrap.grouping引數設定相同的寬度:
library(likert)
levels(freq$Reason) <- stringr::str_wrap(levels(freq$Reason), width = 40)
like <- likert(freq[, 1, drop = FALSE], grouping = freq$Reason)
likert.bar.plot(like, wrap.grouping = 40)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/406994.html
標籤:
下一篇:如何在ggplot中添加圖例