我的資料由時間序列上的 25 個部門組成,我想在折線圖中為每個部門繪制工人數量(系列 1)和平均工資(系列 2),次要 y 軸表示平均工資和主 y 軸表示工人的數量,然后將圖表排列在網格上。
示例資料:
| 時期 | 平均工資 | number_of_workers | 部門 |
|---|---|---|---|
| 1990 | 2000 | 5000 | 建造 |
| 1991 | 2020 | 4970 | 建造 |
| 1992 | 2050 | 5050 | 建造 |
| 1990 | 1000 | 120 | 它 |
| 1991 | 1100 | 400 | 它 |
| 1992 | 1080 | 500 | 它 |
| 1990 | 10000 | 900 | 醫院作業人員 |
| 1991 | 10200 | 980 | 醫院作業人員 |
| 1992 | 10400 | 1200 | 醫院作業人員 |
我嘗試使用 facet_wrap() 作為網格和 scale_y_continuous(sec.axis...) 如下:
#fake sample data for reference
dfa=data.frame(order=seq(1,100),workers=rnorm(1000,7),pay=rnorm(1000,3000,500),type="a") #1st sector
dfb=data.frame(order=seq(1,100),workers=rnorm(1000,25),pay=rnorm(1000,1000,500),type="b") #2nd sector
dfc=data.frame(order=seq(1,100),workers=rnorm(1000,400),pay=rnorm(1000,5000,500),type="c") #3rd sector
df=rbind(dfa,dfb,dfc)
colnames(df)=c(
"order", #shared x axis/time value
"workers", #time series 1 (y values for left side y axis)
"pay", #time series 2 (y values for left side y axis)
"type" #diffrent graphs to put on the grid
)
ggploting資料:
df=df %>% group_by(l=type) %>% mutate(coeff=max(pay)/max(workers)) %>% ungroup() #creating a coefficient to scale the secondry axis
plot=ggplot(data=df,aes(x=order))
geom_line(aes(y=workers),linetype="dashed",color="red")
geom_line(aes(y=pay/coeff))
scale_y_continuous(sec.axis=sec_axis(~.*coeff2,name="wage"))
facet_wrap(~type,scale="free")
但不幸的是,這不起作用,因為你不能在函式 sec_axis() 中使用資料(這個例子甚至沒有運行)。
我嘗試的另一種方法是使用 for 回圈和 grid.arrange():
plots=list()
for (i in (unique(df$type)))
{
singlesector=df[df$type==i,]
axiscoeff=df$coeff[1]
plot=ggplot(data=singlesector,aes(x=order))
geom_line(aes(y=workers),linetype="dashed",color="red")
geom_line(aes(y=pay/coeff)) labs(title=i)
scale_y_continuous(sec.axis=sec_axis(~.*axiscoeff,name="wage"))
plots[[i]]=plot
}
grid.arrange(grobs=plots)
但這也不起作用,因為 ggplot 不保存變數 axiscoeff 的各種值,因此它將第一個值應用于所有圖形。
看結果(右邊的軸亂了,不符合紅線的資料):
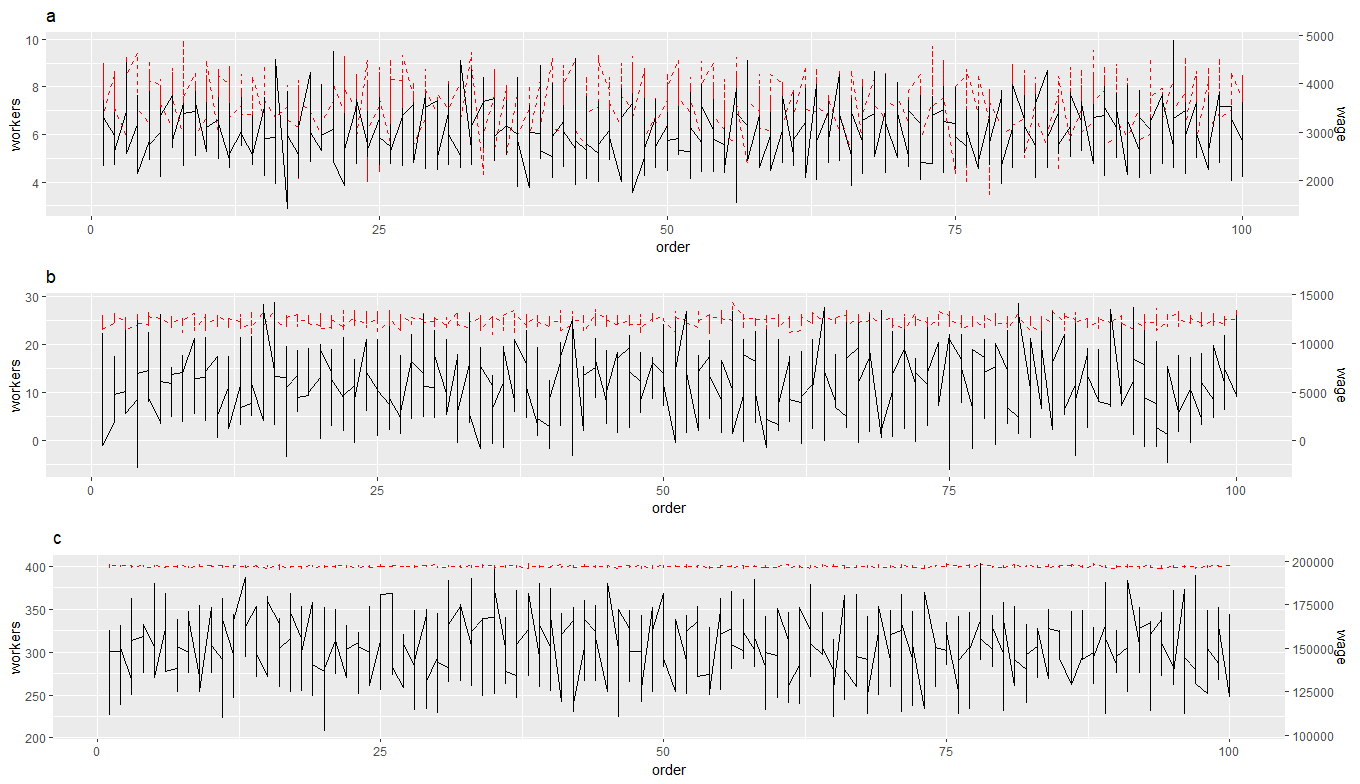
有什么辦法可以做我想做的事嗎?我想也許可以直接將所有地塊分別保存為 png,而不是以其他方式加入它們,但這似乎是一個極端的解決方案,需要花費太多時間才能弄清楚。
uj5u.com熱心網友回復:
據我所知,問題在于您(重新)縮放資料的方式,即使用 max(pay) / max(workers)您重新縮放資料,以便最大值pay映射到最大值workers,但不考慮不同的范圍或變數的分布。
相反,您可以使用scales::rescale重新調整您的資料,以便將 的范圍pay映射到 的范圍workers。
除此之外,我采用了不同的方法將圖粘合在一起,利用patchwork. 為此,我將繪圖代碼放在一個函式中,split資料由type,用于lapply回圈拆分資料,最后使用 將繪圖粘合在一起patchwork::wrap_plots。
注意:由于您的示例資料包含每個訂單/型別的多個值,我稍微更改了它以擺脫鋸齒線。
library(dplyr)
library(ggplot2)
library(patchwork)
library(scales)
df %>%
split(.$type) %>%
lapply(function(df) {
range_pay <- range(df$pay)
range_workers <- range(df$workers)
ggplot(data = df, aes(x = order))
geom_line(aes(y = workers), linetype = "dashed", color = "red")
geom_line(aes(y = rescale(pay, range_workers, range_pay)))
scale_y_continuous(sec.axis = sec_axis(~ rescale(.x, range_pay, range_workers), name = "wage"))
facet_wrap(~type)
}) %>%
wrap_plots(ncol = 1)
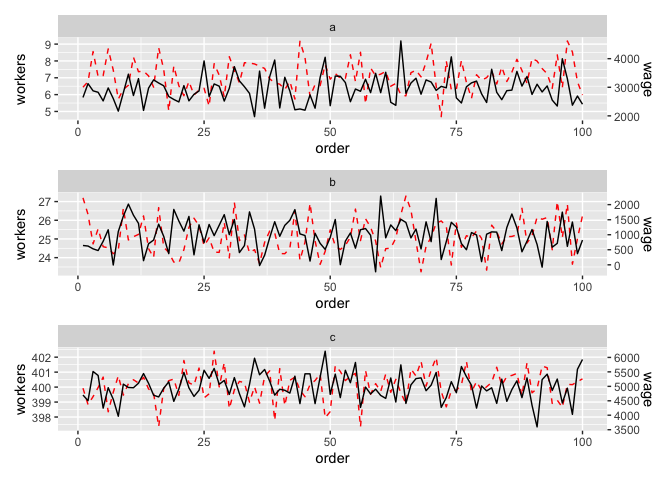
資料
set.seed(123)
dfa <- data.frame(order = 1:100, workers = rnorm(100, 7), pay = rnorm(100, 3000, 500), type = "a") # 1st sector
dfb <- data.frame(order = 1:100, workers = rnorm(100, 25), pay = rnorm(100, 1000, 500), type = "b") # 2nd sector
dfc <- data.frame(order = 1:100, workers = rnorm(100, 400), pay = rnorm(100, 5000, 500), type = "c") # 3rd sector
df <- rbind(dfa, dfb, dfc)
names(df) <- c("order", "workers", "pay", "type")
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/407001.html
標籤:
上一篇:桑基圖時間
下一篇:手動縮放ggplot圖例