請幫忙!
我需要下表中 SalesAgreementID 為 10062 的每個不同 VehicleId 的最高公里值和所有其他相關列。
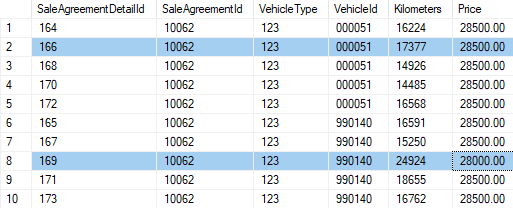
結果應如下所示:
SalesAgreementDetailId | SalesAgreementId | VehicleType | VehicleId | Kilometers | Price
166 | 10062 | 123 | 000051 | 17377 | 28500.00
169 | 10062 | 123 | 990140 | 24924 | 28500.00
嘗試使用:
SELECT DISTINCT VehicleId FROM tblSaleAgreementDetail WHERE SaleAgreementID = '10062';
但它沒有回傳我需要的所有其他列,包括最高公里。
VehicleId |
000051 |
990140 |
太棒了!
uj5u.com熱心網友回復:
在這種情況下,您可以這樣做:
select * from tbl where id = 'xxx' group by field
或這個。
select distinct on field * from table
uj5u.com熱心網友回復:
我們通常做kilometers的是按所需的列(這就是分析函式的用途。
剩下的就是選擇排名“最高”的值。
像這樣的東西:
SQL> with hikm as
2 (select t.*,
3 rank() over (partition by vehicleid order by kilometers desc) rnk
4 from test t
5 )
6 select *
7 from hikm
8 where rnk = 1;
SALEAGREEMENTDETAILID SALEAGREEMENTID VEHICLETYPE VEHICL KILOMETERS RNK
--------------------- --------------- ----------- ------ ---------- ----------
166 10062 123 000051 17377 1
169 10062 123 990140 24924 1
SQL>
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/411046.html
標籤: