在 R 中,我有一個資料框,其中包含以隨機順序呈現的影像索引 (i1,i2,i3) 以及每個影像的評級 (a1,a2,a3):
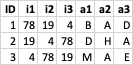
現在我想添加新變數,以升序(i1_s,i2_s,i3_s)表示呈現影像的索引。這種重新排序也必須應用于相應的答案(a1_s,a2_s,a3_s)。所以最終的資料框應該是這樣的:
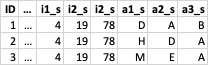
我怎樣才能在 R 中完成這項任務?我認為這應該是一項非常常見的任務,必須在隨機研究設計中完成很多作業,但我找不到操作方法或教程。問題是,我不知道這種操作的正確技術術語。
注意:由于在實際研究中存在數百個影像變數和答案變數,因此高度贊賞對變數名稱模式進行操作的通用方法!
編輯:為上述示例資料添加代碼:
df <- data.frame(
ID = c("1", "2", "3"),
i1 = c(78, 19, 4),
i2 = c(19, 4, 78),
i3 = c(4, 78, 19),
a1 = c("B", "D", "M"),
a2 = c("A", "H", "A"),
a3 = c("D", "A", "E"),
i1_s = c(NA,NA,NA),
i2_s = c(NA,NA,NA),
i3_s = c(NA,NA,NA),
a1_s = c(NA,NA,NA),
a2_s = c(NA,NA,NA),
a3_s = c(NA,NA,NA)
)
uj5u.com熱心網友回復:
這是另一種tidyverse方法。您可以names_pattern在將資料轉換為長格式時提供。arrange使用for each對值進行排序后,如果需要ID,您可以pivot_wider放回寬格式。
編輯:由于以“_s”結尾的i1_s、i2_s等列是從腳本自動生成的,因此您無需提前創建“空”列。對于這個例子,我只是洗掉了它們。
library(tidyverse)
df %>%
select(-(i1_s:a3_s)) %>%
pivot_longer(cols = -ID,
names_to = c(".value", "number"),
names_pattern = "(\\w )(\\d )") %>%
group_by(ID) %>%
arrange(i) %>%
mutate(number = row_number()) %>%
pivot_wider(id_cols = ID,
names_from = number,
names_glue = "{.name}_s",
values_from = c(-ID, -number),
names_sep = "")
輸出
ID i1_s i2_s i3_s a1_s a2_s a3_s
<chr> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 1 4 19 78 D A B
2 2 4 19 78 H D A
3 3 4 19 78 M E A
uj5u.com熱心網友回復:
很想知道其他人是如何做到這一點的,但這是一種解決方案。
df %>%
as_tibble() %>%
mutate(across(-ID, as.character)) %>%
pivot_longer(cols = -ID) %>%
mutate(
num = substring(name,2),
name = substring(name,1,1)
) %>%
pivot_wider(
names_from = name
) %>%
mutate(
i = as.numeric(i)
) %>%
arrange(ID, i) %>%
group_by(ID) %>%
mutate(
rank1 = row_number()
) %>%
mutate(
i = as.character(i)
) %>%
pivot_longer(cols = c(i,a)) %>%
mutate(
name = paste0(name, rank1, '_s')
) %>%
select(-num, -rank1) %>%
arrange(ID, name) %>%
pivot_wider() %>%
mutate(across(starts_with('i'), as.numeric))
輸出:
ID a1_s a2_s a3_s i1_s i2_s i3_s
<int> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 1 D A B 4 19 78
2 2 H D A 4 19 78
3 3 M E A 4 19 78
資料:
df <- structure(list(ID = 1:3, i1 = c(78L, 19L, 4L), i2 = c(19L, 4L,
78L), i3 = c(4L, 78L, 19L), a1 = c("B", "D", "M"), a2 = c("A",
"H", "A"), a3 = c("D", "A", "E")), class = "data.frame", row.names = c(NA,
-3L))
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/411329.html
標籤:
上一篇:MySQL基于乘法“LIKE”對結果進行特定排序并更好地匹配已建立的結果
下一篇:“with”子句表的內連接結果