我有兩個表,第一個'A'包含大約 400k 行和表'B' - 12k 行。我需要從表 A 和 INSERT 中選擇 ~350k 行到表 B。
我在存盤程序中執行此操作(因為我需要執行許多其他任務):
INSERT INTO B ("fields")
SELECT "field"
FROM A
INNER JOIN @TempTable -- this join need for filtering records in table A
表結構
表 A:
CREATE TABLE [dbo].[A]
(
[Field1] [uniqueidentifier] NOT NULL,
[Field2] [int] NOT NULL,
[Field3] [uniqueidentifier] NOT NULL,
[Field4] [nvarchar](max) NULL,
[Field5] [bit] NOT NULL,
[Field6] [int] NULL,
[Field7] [tinyint] NULL,
CONSTRAINT [PK_A]
PRIMARY KEY CLUSTERED ([Field1] ASC, [Field2] ASC, [Field3] ASC)
WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[A] WITH CHECK
ADD CONSTRAINT [FK_...]
FOREIGN KEY([Field2]) REFERENCES [dbo].[...] ([Id])
GO
ALTER TABLE [dbo].[A] WITH CHECK
ADD CONSTRAINT [...]
FOREIGN KEY([Field3]) REFERENCES [dbo].[...] ([Id])
GO
ALTER TABLE [dbo].[A] WITH CHECK
ADD CONSTRAINT [...]
FOREIGN KEY([Field1]) REFERENCES [dbo].[A] ([Id])
GO
表 B:
CREATE TABLE [dbo].[B]
(
[Field1] [uniqueidentifier] NOT NULL,
[Field2] [int] NOT NULL,
[Field3] [uniqueidentifier] NOT NULL,
[Field4] [tinyint] NULL,
[Field5] [nvarchar](max) NULL,
[Field6] [bit] NOT NULL,
[Field7] [int] NULL,
CONSTRAINT [PK_B]
PRIMARY KEY CLUSTERED ([Field1] ASC, [Field2] ASC, [Field3] ASC)
WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[B] WITH CHECK
ADD CONSTRAINT [...]
FOREIGN KEY([Field2]) REFERENCES [dbo].[...] ([Id])
GO
ALTER TABLE [dbo].[B] WITH CHECK
ADD CONSTRAINT [...]
FOREIGN KEY([Field3]) REFERENCES [dbo].[...] ([Id])
GO
ALTER TABLE [dbo].[B] WITH CHECK
ADD CONSTRAINT [...]
FOREIGN KEY([Field1]) REFERENCES [dbo].[...] ([Id])
GO
基礎設施:
- SQL Azure 資料庫(計劃 S1 - 20 DTU)
- 另外,我使用 Entity Framework Core 來執行這個存盤程序
使用我提到的配置,插入操作需要 1:55 分鐘,我嘗試只運行不插入的選擇只需要 3-5 秒,這意味著插入有問題。
我已經嘗試過的解決方案:
1. I have removed all indexes before inserting. that improves performance, takes only 45 sec, but indexes anyway should be created after inserting. Indexes recreation takes ~1 min so we get same ~1:55 min. And 45 sec is still a long time.
2. I tried to insert using batches (by 5000), this reduce only to 1:35 min.
Additional info: We can't increase "DTU" significantly because when the application works in regular mode it does not need more than 80% of this resource (S1 - 20 DTU)
Execution plan (with indexes):
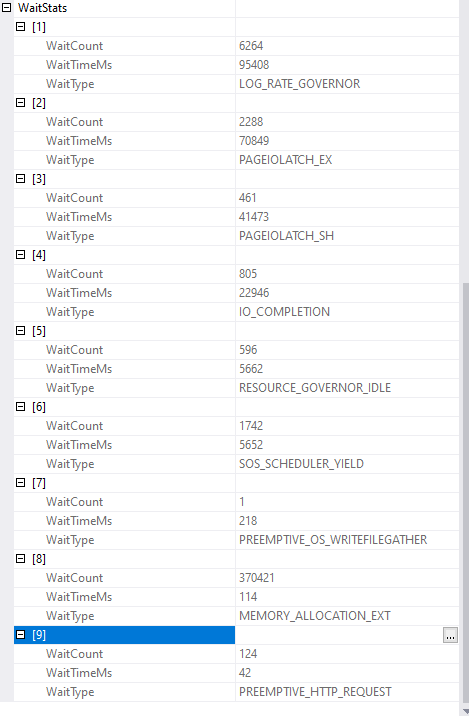
PAGEIOLATCH_EX是等待寫入磁盤,PAGEIOLATCH_SH是等待從磁盤讀取,LOG_RATE_GOVERNOR本質上也是IO等待,等待寫入日志檔案。20DTU 資料庫的 IO 和 Log 寫入限制非常小,標準層 DTU 模型僅提供1-4 IOPS/DTU,因此低于 100 IOPS。
所以你可以
- 少寫資料
- 通過消除列,特別是nvarchar(max)如果它很大的列
-通過使用頁面壓縮或聚集列存盤索引壓縮資料,或者nvarchar(max)如果列很大,則使用 COMPRESS TSQL 函式
或者
- 提供更多資源
- 通過擴展至更高的 DTU、VCore 配置或具有彈性擴展的無服務器配置
- 通過遷移到在每個服務級別提供 100MB/S 日志吞吐量的超大規模
-將此資料庫移動到一個彈性池中,它可以與其他資料庫共享更大的資源池。
表磁區不會減少寫入量。并且記憶體中 OLTP 僅在已具有更高 IOPS 的高級/關鍵業務層中可用。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/413279.html
標籤:
下一篇:植物學庫——最快的數字簽名驗證