LCI.materials <- read.csv('LCImaterials.csv')
LCA.bridge <- function(length, width, height, thickness, girder.Option, deck.Option, materials) {
prefab.girder.Section <- 0.78
steel.girders.unitWeight <- 317 #the weight for HEM800 steel profile
asphalt.Q <- length * width * thickness
materials.split <- split(materials, materials$scope)
# calculate the volume of the deck based on different materials strategies
if(deck.Option == "RC") {
deck.volume <- length * width * height
interventions.deck <- 2.5
} else if (deck.Option == "PRC") {
deck.volume <- 0.5 * length * width * height
interventions.deck <- 2
} else if (deck.Option == "FRP") {
deck.volume <- 0.2 * length * width * height
interventions.deck <- 1
}
#girder options
if (girder.Option == "PRC") {
#get the numbers of girders
n <-round(width / 3.75, 0)
interventions.girders <- 2
#get the volume of the concrete for the prefab girders
girders.V <- n * prefab.girder.Section * length
} else if (girder.Option == "steel") {
n <- round(width / 3, 0)
girders.V <- n * steel.girders.unitWeight * length
interventions.girders <- 2
} else if (girder.Option == "none") {
n <- 0
girders.V <- 0
interventions.girders <- 0
}
asphalt <- mutate(materials.split$asphalt, bridge.Q = asphalt.Q, interventions = 12)
deck <- mutate(materials.split[[deck.Option]], bridge.Q = deck.volume, interventions = interventions.deck)
if (!is.null(materials.split[[girder.Option]])) {
girders <- mutate(materials.split[[girder.Option]], bridge.Q = girders.V, interventions = interventions.girders)
LCA.matrix <- rbind(deck, girders, asphalt)
} else {
LCA.matrix <- rbind(deck, asphalt)
}
LCA.matrix <- mutate(LCA.matrix, TotalMaterials.Q = **strong text**quantities * bridge.Q / 1000,
materials.LC = TotalMaterials.Q * interventions,
Energy.LC = materials.LC * energy,
CO2.LC = materials.LC * CO2 * 1000,
NOx.LC = materials.LC * NOx * 1000,
SO2.LC = materials.LC * SO2 * 1000)
LCA.results <- list(Energy = sum(LCA.matrix$Energy.LC),
CO2 = sum(LCA.matrix$CO2.LC),
NOx = sum(LCA.matrix$NOx.LC),
SO2 = sum(LCA.matrix$SO2.LC))
return(LCA.results)
}
b.length <- 16 # units: m
b.width <- 15 #units m
bd.depth <- 0.25 #units m
asphalt.tk <- 0.12 #units m
girder.Options <- c("PRC", "steel", "none")
deck.options <- c("RC", "PRC", "FRP")
Option1 <- LCA.bridge(b.length, b.width, bd.depth, asphalt.tk, girder.Options[1], deck.options[1], LCI.materials)
大家好。此 R 功能完全可以正常作業,沒有任何問題。它正在從 excel 中讀取一個小表格。我在問這個。這個函式如何才能很好地理解和閱讀數量列?我把它加粗了。我正在做與此功能類似的事情,但我總是收到錯誤訊息:
LCA.bridge 中的錯誤(b.length,b.width,b.height,b.thickness,column.Options 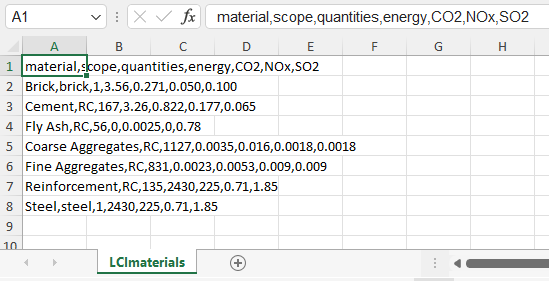
我想了解第一個代碼如何從小表中識別/理解/找到“數量”?我們如何使用 dplyr 和 mutate 從 R 中的 CSV 檔案中讀取列?你能給我解釋一下嗎?提前致謝。
uj5u.com熱心網友回復:
LCA.matrix <- c(LCA.matrix |
mutate(TotalMaterials.Q = quantities * bridge.Q / 1000) |
mutate(materials.LC = TotalMaterials.Q * interventions) |
mutate(Energy.LC = materials.LC*energy) |
mutate(CO2.LC = materials.LC*CO2*1000) |
mutate(NOx.LC = materials.LC*NOx*1000) |
mutate(SO2.LC = materials.LC*SO2*1000))
感謝您的想法,我洗掉了以前的并嘗試添加這個。但是仍然找不到bridge.Q。我無法理解這個問題。
uj5u.com熱心網友回復:
代碼的第一行讀取 .csv 檔案并將其傳輸到名為 LCI.materials 的 data.frame 物件:
LCI.materials <- read.csv('LCImaterials.csv')
為了測驗 p 目的,我用 2 行創建了這樣的檔案并加載了它。如果我們想看看里面有什么,head()函式會有所幫助:
head(LCI.materials)
material scope quantities energy CO2 NOx SO2
1 Brick brick 1 3.56 0.271 0.050 0.100
2 Cement RC 167 3.26 0.822 0.177 0.065
如您所見,這些列對應于您在.csv檔案中的這些列,包括quantities.
function的最后一個引數LCA.bridge是 named materials,當你在代碼的最后一行呼叫這個函式時:
Option1 <- LCA.bridge(b.length, b.width, bd.depth, asphalt.tk, girder.Options[1], deck.options[1], LCI.materials)
你materials用LCI.materials資料框代替。在內部,函式將 拆分LCI.materials為scope:
materials.split <- split(materials, materials$scope)
還有另一個觀察:您的LCA.bridge函式asphalt在材料資料框中查找:
asphalt <-
mutate(materials.split$asphalt,
bridge.Q = asphalt.Q,
interventions = 12)
但是,在您的示例中(在小表中)沒有這樣的材料。這可能是個問題嗎?
格熱戈日
uj5u.com熱心網友回復:
LCI.materials <- read.csv('LCImaterials.csv')
LCA.bridge <- function(length, width, height, thickness, column.Option, abutment.Option, materials) {
steel.unitWeight <- 317 #the weight for HEM800 steel profile
materials.split <- split(materials, materials$scope)
#column options
if(column.Option == "RC") {
column.volume <- length * width * height
interventions.column <- 2
} else if (column.Option == "steel") {
column.volume <- length * width * height * thickness * steel.unitWeight
interventions.column <- 3
}
#abutment options
if (abutment.Option == "RC") {
abutment.volume <- height * length * 5 # 2 * height * length * 5 / 2
interventions.abutment <- 2
} else if (abutment.Option == "brick") {
abutment.volume <- height * length * 5 # 2 * height * length * 5 / 2
interventions.abutment <- 2
}
column <- dplyr::mutate(materials.split[[column.Option]], bridge.Q = column.volume, interventions = interventions.column)
abutment <- dplyr::mutate(materials.split[[abutment.Option]], bridge.Q = abutment.volume, interventions = interventions.abutment)
LCA.matrix <- rbind(column, abutment)
quantities <- split(materials, materials$quantities)
LCA.matrix <- c(LCA.matrix, TotalMaterials.Q = quantities * bridge.Q / 1000,
materials.LC = TotalMaterials.Q * interventions,
Energy.LC = materials.LC * energy,
CO2.LC = materials.LC * CO2 * 1000,
NOx.LC = materials.LC * NOx * 1000,
SO2.LC = materials.LC * SO2 * 1000)
LCA.results <- list(Energy = sum(LCA.matrix$Energy.LC),
CO2 = sum(LCA.matrix$CO2.LC),
NOx = sum(LCA.matrix$NOx.LC),
SO2 = sum(LCA.matrix$SO2.LC))
return(LCA.results)
}
b.length <- 5
b.height <- 5
b.width <- 2
b.thickness <- 0.05
column.Options <- c("RC","steel")
abutment.Options <- c("brick","RC")
Option1 <- LCA.bridge(b.length, b.width, b.height, b.thickness, column.Options[1], abutment.Options[1], LCI.materials)
謝謝你的回答。這很有用。實際上,這是我的代碼和該代碼之前的小表格。所以瀝青沒有問題。感謝您的想法,我添加了這一行。它奏效了。
quantities <- split(materials, materials$quantities)
但現在它可以找到bridge.Q。這些還不足以讓R找到bridge.Q嗎?我在這些變異中寫了 bridge.Q = column.volume。我該怎么辦@Grzegorz Sapijaszko?
column <- dplyr::mutate(materials.split[[column.Option]], bridge.Q = column.volume, interventions = interventions.column)
abutment <- dplyr::mutate(materials.split[[abutment.Option]], bridge.Q = abutment.volume, interventions = interventions.abutment)
uj5u.com熱心網友回復:
它很有用,但是 mutate 還有另一個問題
不知道你想在這部分實作什么:
LCA.matrix <- c(LCA.matrix, TotalMaterials.Q = quantities * bridge.Q / 1000,
materials.LC = TotalMaterials.Q * interventions,
Energy.LC = materials.LC * energy,
CO2.LC = materials.LC * CO2 * 1000,
NOx.LC = materials.LC * NOx * 1000,
SO2.LC = materials.LC * SO2 * 1000)
如果打算計算額外的列,如 TotalMaterials.Q 等,則使用 mutate:
LCA.matrix <- LCA.matrix |>
mutate(TotalMaterials.Q = quantities * bridge.Q / 1000) |>
mutate(materials.LC = TotalMaterials.Q * interventions)
[...]
問候, 格熱戈日
uj5u.com熱心網友回復:
LCA.matrix <- LCA.matrix |>
mutate(TotalMaterials.Q = quantities * bridge.Q / 1000) |>
mutate(materials.LC = TotalMaterials.Q * interventions) |>
mutate(Energy.LC = energy ) |>
mutate(CO2.LC = CO2 * 1000) |>
mutate(NOx.LC = NOx*1000) |>
mutate(SO2.LC = SO2*1000)
應該做的伎倆
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/419377.html
標籤:
上一篇:使用stringr提取模式
下一篇:將多個子標題轉換為R中的因子列