data = {'city':['Austin TX', 'Austin TX', 'Austin TX', 'Columbus OH', 'Columbus OH', 'Columbus OH', 'Columbus OH', 'Dallas TX', 'Dallas TX' , 'Dallas TX', 'Dallas TX' , 'Dallas TX'],
'a1':[20, 200, 300, 400, 1000, 500, 800, 900, 900, 1000, 200, 450], 'a2':[30, 100, 1000, 500, 400, 600, 340, 430, 230, 450, 670, 780]}
我想檢查第二行的城市是否與第一行相同,如果是,那么我必須獲取該城市的資料。我需要的最終輸出是包含每個城市資料的單獨資料框或 excel 表或 csv。例如,對于 Austin TX,將有一個名為“Austin_excel”的 Excel 表,其中包含 Austin 的資料,前 3 行為 a1、a2 和城市。
uj5u.com熱心網友回復:
我想這就是你想要的 -
import pandas as pd
df = pd.DataFrame(data)
workbook = pd.ExcelWriter("City Data.xlsx", engine="xlsxwriter")
for city, city_data in df.groupby("city"):
city_data.to_excel(workbook, sheet_name=city)
workbook.save()
輸出看起來像 -
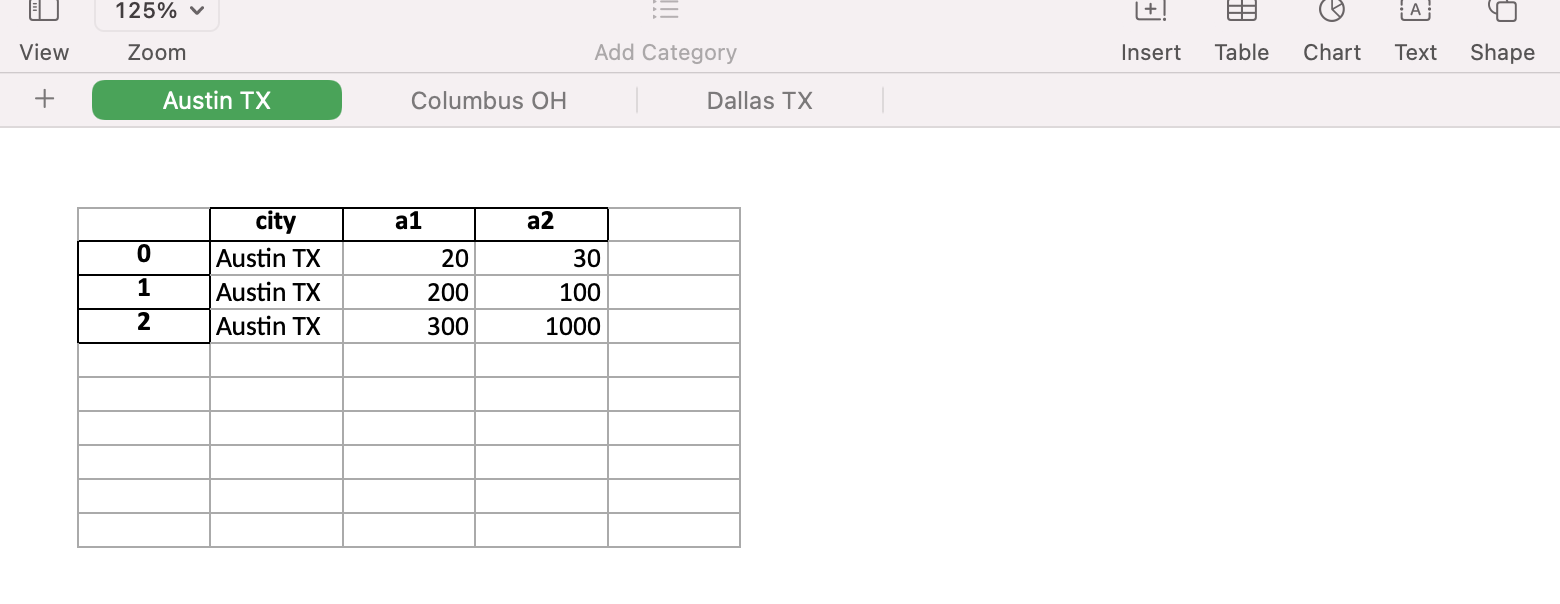
根據需要,資料位于 Excel 作業簿的單獨作業表中。
uj5u.com熱心網友回復:
您可以使用 to_excel 將 Pandas DataFrame 匯出到 Excel 檔案。
這是您可以在 Python 中應用以匯出 DataFrame 的模板:
df.to_excel(r'匯出的excel檔案存放的路徑\File Name.xlsx', index = False) 例如:
import pandas as pd
data = {'Product': ['Desktop Computer','Printer','Tablet','Monitor'],
'Price': [1200,150,300,450]
}
df = pd.DataFrame(data, columns = ['Product', 'Price'])
print (df)
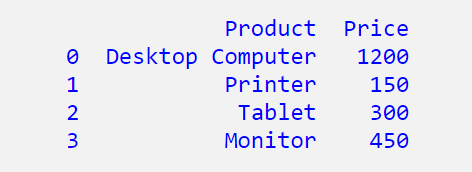
然后你可能會得到這個:
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/419966.html
標籤: