
編者按:本文源自阿里云云效團隊出品的《阿里巴巴DevOps實踐指南》,掃描上方二維碼或前往:https://developer.aliyun.com/topic/devops,下載完整版電子書,了解阿里十年DevOps實踐經驗,
阿里巴巴的運維體系經歷了腳本時代、工具時代和 DevOps 時代,目前正在實作自動化運維并探索智能化運維階段,在 2008-2009 年,阿里巴巴的運維還處于腳本時代,大量的運維作業需要通過腳本來實作,隨著業務規模擴大和復雜度的提高,腳本的方式越來越難以維護,因此阿里巴巴開始引入運維工具,在運維工具時代,阿里巴巴的運維體系經歷了:從工具團隊和運維團隊并行的階段,到為了更好地保障工具質量統一的工具團隊階段,再到逐漸有 DevOps 思想和職能的偏軟體的工具團隊階段,最后,阿里巴巴應用運維團隊迎來了一場大變革,以前的應用運維團隊全被打散,合并到各業務的軟體開發團隊中去,全面踐行 DevOps 思想,

進入 DevOps 階段后,成熟的流程化運維工具雖然提升了一部分運維效率,但是各個工具之間實際是獨立割裂的,例如監控工具和運維工具是割裂的,巡檢工具和快恢工具也是割裂的,這導致日常應用持續運維程序中,從監控發現、定位并快速恢復問題的鏈路很長而且低效,對運維開發來說,期望的狀態是業務應用上線后可以“No Ops”,監控及運維系統能自行發現例外并自動解決,把應用及業務帶回正常狀態,處理結束后,發一個訊息通知下即可, 朝著“No Ops”方向努力,阿里巴巴應用運維開始了“監管控一體化”的體系建設,
新挑戰
隨著阿里巴巴業務的持續發展及技術架構地不斷演進,新的場景和問題不斷出現,這些都給以應用為中心的監控運維帶來了新的挑戰,
超大規模
阿里巴巴不但擁有眾多形態各異的業務,而且體量大,特別是每年天貓雙 11 大促,需要超大規模的 IAAS 資源支撐,2015 年之前,阿里巴巴每年都要花費巨額費用來購買服務器,建設一代又一代的 IDC 資料中心;2015 年至 2019 年,阿里巴巴走向全面云化的程序,在這個時期,阿里巴巴的基礎設施一部分在云下資料中心,另一部分在阿里云上的資料中心,還需要支持同城多活到異地多活,所以必須要有強大的云上云下一體化超大規模資源管理的能力;2019 年阿里巴巴實作全面云化之后,又開始面對一個新的超大規模資源管理場景:混合云,
運維效率
業務發展瞬息萬變,特別是公司的重要業務,迭代變更的速度非常快,在超大規模集群管理的前提下,為了保障業務的連續性和快速迭代,我們需要有能力持續高效地對應用進行發布、部署、變配等運維變更,這也就是 DevOps 的持續運維領域要去解決的問題,
運維安全
安全性是任何行業的基礎,在 IT 運維領域更是如此,系統宕機、資料例外、資料丟失、刪庫跑路等運維故障和事件層出不窮,這可能給企業帶來致命的打擊,甚至關乎業務的生死存亡,因此,防范和杜絕高危運維故障是 DevOps 一直不懈追求的目標,在當代眾多業務形態和云技術架構下,如何保障企業 IT 運維的安全運行至關重要,
業務連續性
在阿里巴巴傳統的監控和運維模式下,應用的運維開發需要在監控系統上配置一些監控項和預警規則,當監控項觸發預警規則時,運維開發會收到預警通知,緊接著運維開發需要打開電腦,在運維工具平臺上創建相應的處理工單,當運維系統工單執行完成后,運維開發要持續觀察監控項是否回歸正常,若遇到節假榷訓休假期間接到預警通知,不能及時上線查看情況時還需要聯系團隊其他同學上線處理;若在半夜睡夢中接到預警通知,需要立馬清醒下自己的大腦,打開電腦上線處理,整個預警例外處理程序持續時間較長,并且需要人為參與的作業很多,人力成本大,這使得運維開發的作業幸福感很低,
另一方面,隨著業務地不斷發展,系統也在不斷增加,監控項和預警也急速增多,慢慢地運維開發就會對預警資訊變得麻木或輕視,容易錯失一些重要的報警資訊,進而導致線上業務故障,近年來,淘寶直播、盒馬線下門店、餓了么外賣、釘釘在線教育等新業務形態蓬勃發展,這些業務基本上對生產故障都是零容忍,原來系統最佳的 99.99%可用性已經不能滿足新業務的要求,而傳統的監控、運維各自為戰、單打獨斗的模式更無法滿足新業務 100%業務連續性的要求,
解決思路
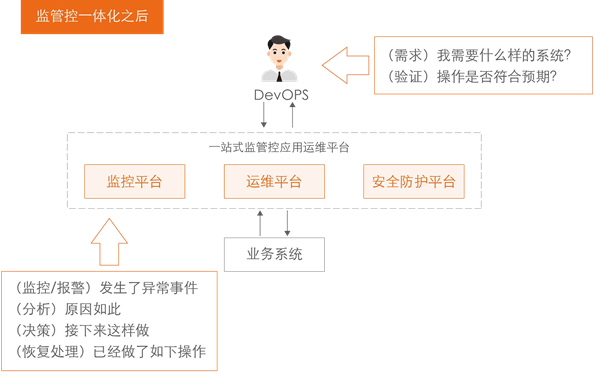
為了保證生產業務的連續運行,提高業務系統從例外預警到例外恢復的整體效率,解放人力成本的同時又能確保安全,我們考慮將監控預警和運維執行聯動起來,視為一體,從而實作例外自動發現、自動快速定位以及自動快速恢復的目的,達到一種“No Ops”狀態的應用運維,
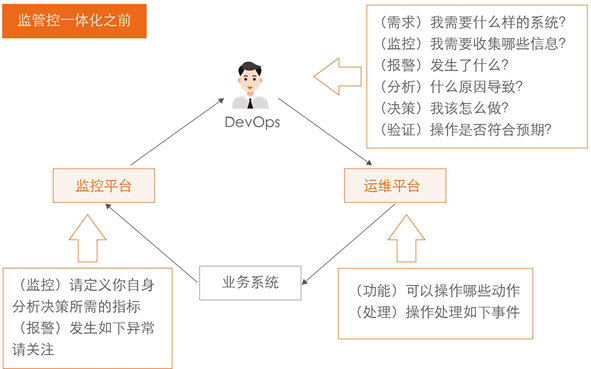
在應用監管控一體化建設之前,傳統的監控和運維是分開的狀態,運維開發想要在應用迭代變更期間關注系統運行態勢,需要事前在監控平臺上定義和配置好這些應用所要關注的各項指標,在應用變更期間需要不斷主動查看應用監控指標的變化,或者為每個指標設定預警規則,通過訂閱接收配置好的監控報警來及時獲取應用的運行例外,當應用變更出現例外報警后,運維開發需要看監控、應用日志、應用呼叫鏈路等資訊分析例外原因,決策需要到運維平臺上執行什么任務才能恢復,最后驗證任務執行結果是否符合預期,因此,明確需求->配置監控指標和報警->分析例外原因->決策處理方式->執行任務->驗證執行結果,整個程序都需要運維開發的介入,
解決方案
以保障業務持續性為源動力,在逐步推進監管控一體化建設程序中,阿里巴巴從實戰經驗沉淀出一套業務系統安全工程標準,實作了業務例外故障提前發現、自動定位、快速恢復地自動聯動,在監控、運維、安全防護領域探索出了多樣化的解決方案,
安全防護
在推進 DevOps 的程序中,我們要求的底線是不能對既有的現狀帶來更多不可控的因素,特別是高危場景的防護,不能因為運維作業移交到運維開發人員而造成全域系統性風險,因此安全防護方案孕育而生,
全景監控
監控是運維的基礎,傳統的資源監控或者應用監控模式已經不能滿足運維開發快速發現生產故障的需求,基于阿里的大規模實踐,我們發展出了以應用為中心,從上層業務到 PaaS 直至底層資源的全鏈路監控解決方案,為業務例外發現和定位提供了強有力的支撐,
多樣化運維
為了實作監管控一體化,促進業務例外能快速自動恢復,應用運維從原來的單事件執行模式,探索出以應用為中心的可編排運維、智能化運維、ChatOps 等運維模式,打開運維領域新視角,
總結
阿里巴巴應用運維監管控一體化的建設隨著業務形態和技術架構還在不斷地探索和發展,本文主要介紹了應用運維監管控一體化建設的背景和思路,我們以應用為中心,從應用監控管角度出發,通過全視角監控實時掌握應用的運行狀態,通過高效發布部署和靈活的運維編排對應用進行安全變更,通過智能化運維和安全防護實作應用的高級防護,我們將在下面的章節為你詳細展開,
【關于云效】
云效,云原生時代一站式BizDevOps平臺,支持公共云、專有云和混合云多種部署形態,通過云原生新技術和研發新模式,助力創新創業和數字化轉型企業快速實作研發敏捷和組織敏捷,打造“雙敏”組織,實作 10 倍效能提升,
立即體驗

轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/421839.html
標籤:其他