我有一個 CSV 檔案,其中包含兩個模型(模型 1 和模型 2)的經緯度值,如下所示。我正在努力實作以下目標
- 搜索每行列值
Lat/ Long的第一行值。如果在模型 2 中找到模型 1 的緯度/經度值,則在新列中列印它們各自的區域名稱,例如“Papa”。對模型 1 中的其余行重復該程序,然后將模型 2。model 1model 2Lat/ Long - 如果模型 1 的
Lat/Long值與模型 2 不匹配,則在輸出NOT matched中列印。``
最小的作業示例:
import pandas as pd
df3= pd.read_csv("compare.csv")
Output=df3.loc[:, df3.columns.isin(list('LatLong'))]
搜索現有答案 ( 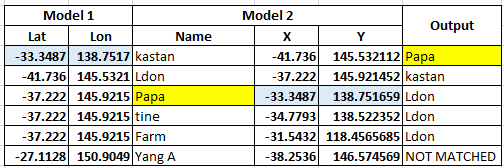
uj5u.com熱心網友回復:
一種使用方式pandas.merge:
df["Output"] = df["Model 1"].merge(df["Model 2"],
how="left",
left_on=["Lat", "Lon"],
right_on=["X", "Y"],
)["Name"].fillna("NOT MATCHED")
輸出:
Model 1 Model 2 Output
Lat Lon Name X Y
0 -33.348652 138.751659 Bastyan -41.735983 145.532112 Papa
1 -41.735983 145.532112 Eildon -37.222005 145.921452 Bastyan
2 -37.222005 145.921452 Papa -33.348652 138.751659 Eildon
3 -37.222005 145.921452 Quar -34.779284 138.522352 Eildon
4 -37.222005 145.921452 Coll -31.543177 118.456569 Eildon
5 -27.112811 150.904878 Loy -38.253600 146.574569 NOT MATCHED
使用的樣本資料:
from io import StringIO
data = """Model 1,Model 1,Model 2,Model 2,Model 2
Lat,Lon,Name,X,Y
-33.348652,138.751659,Bastyan,-41.735983,145.532112
-41.735983,145.532112,Eildon,-37.222005,145.921452
-37.222005,145.921452,Papa,-33.348652,138.751659
-37.222005,145.921452,Quar,-34.779284,138.522352
-37.222005,145.921452,Coll,-31.543177,118.4565685
-27.112811,150.904878,Loy,-38.2536,146.574569"""
df = pd.read_csv(StringIO(data), sep=",", header=[0,1])
uj5u.com熱心網友回復:
另一種方法是
#洗掉多級列并交叉合并
s=df.droplevel(level=0, axis=1).merge(df.droplevel(level=0, axis=1), how='cross', suffixes=('','_y'))
#過濾匹配的row_wise并重命名列
#s[((s['Y_y']==s['Lon'])|(s['X_y']==s['Lat']))].filter(regex='_y$', axis=1).rename(columns=lambda x: x.split('_')[0])
s[((s['Y_y']==s['Lon'])|(s['X_y']==s['Lat']))].filter(regex='_y$|Name', axis=1).rename(columns={'Name_y':'Output'}).rename(columns=lambda x: x.split('_')[0])
結果
Name Lat Lon Output X Y
2 Bastyan -37.222005 145.921452 Papa -33.348652 138.751659
6 Eildon -33.348652 138.751659 Bastyan -41.735983 145.532112
13 Papa -41.735983 145.532112 Eildon -37.222005 145.921452
19 Quar -41.735983 145.532112 Eildon -37.222005 145.921452
25 Coll -41.735983 145.532112 Eildon -37.222005 145.921452
uj5u.com熱心網友回復:
試試這個
import pandas as pd
df3 = pd.read_csv("compare.csv", header=[1])
df3['Output'] = df3[['Lat', 'Lon']].merge(df3[['Name', 'X','Y']],
how="left",
left_on=["Lat", "Lon"],
right_on=["X", "Y"])["Name"].fillna("NOT MATCHED")
cols = pd.MultiIndex.from_product([["Model 1"], df3.columns[:2]])
cols = cols.append(pd.MultiIndex.from_product([["Model 2"], df3.columns[2:]]))
df3.columns = cols
print(df3)
輸出
Model 1 Model 2
Lat Lon Name X Y Output
0 -33.348652 138.751659 Bastyan -41.735983 145.532112 Papa
1 -41.735983 145.532112 Eildon -37.222005 145.921452 Bastyan
2 -37.222005 145.921452 Papa -33.348652 138.751659 Eildon
3 -37.222005 145.921452 Quar -34.779284 138.522352 Eildon
4 -37.222005 145.921452 Coll -31.543177 118.456569 Eildon
5 -27.112811 150.904878 Loy -38.253600 146.574569 NOT MATCHED
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/422020.html
標籤:
上一篇:在不與SQL驅動程式耦合的情況下,在Go中處理資料庫錯誤的最佳方法是什么?
下一篇:如何使用輸入標簽更新資料庫中的值