我想快速看一下下面的分布函式,并注意到我嘗試這樣做的方式有很大問題。將函式應用于 時x_range,所有值最終都是0。我對此感到非常困惑,并且很難理解為什么會這樣。在這種情況下我使用 numpy 錯誤嗎?至少這是我唯一的解釋,但我無法找到任何解釋為什么我會看到這些結果。
下面是我的代碼。
from matplotlib import pyplot as plt
import numpy as np
def F(x):
return 0 if x <= 0 \
else .0025 * x if x <= 100 \
else .25 if x <= 200 \
else .0025 * x - .25 if x <= 300 \
else .0025 * x if x <= 400 \
else 1
x_range = np.linspace(0, 410, 1000)
plt.plot(np.vectorize(F)(x_range))
plt.show()
另外,有沒有人知道一種更優雅的方式來簡單地在一個區間內繪制一個函式?我真的不喜歡將函式矢量化并將其應用于專門生成的陣列以僅用于繪圖目的。我認為應該有內置的 matplotlib 功能來在R.
uj5u.com熱心網友回復:
的檔案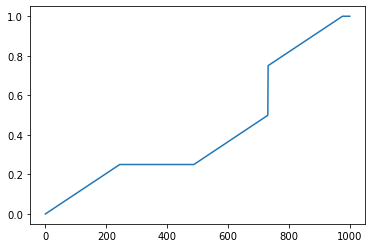
uj5u.com熱心網友回復:
也許將“if statements”中的數字從 int 更改為 float 可能會有所幫助:
def F(x):
return 0.0 if x <= 0.0 \
else 0.0025 * x if x <= 100.0 \
else 0.25 if x <= 200.0 \
else 0.0025 * x - 0.25 if x <= 300.0 \
else 0.0025 * x if x <= 400.0 \
else 1.0
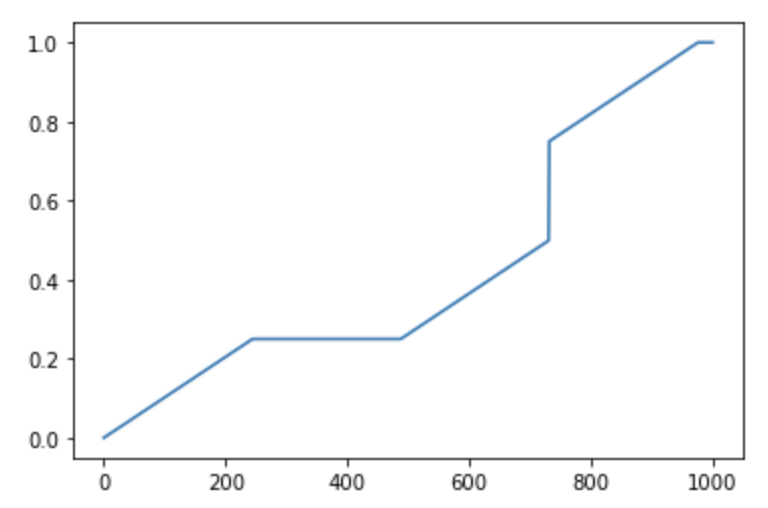
uj5u.com熱心網友回復:
更正F以始終回傳浮點數:
In [45]: def F(x):
...: return .0 if x <= 0 \
...: else .0025 * x if x <= 100 \
...: else .25 if x <= 200 \
...: else .0025 * x - .25 if x <= 300 \
...: else .0025 * x if x <= 400 \
...: else 1.0
...:
還有一個更小的x:
In [46]: x = np.linspace(0,410,11)
In [47]: x
Out[47]: array([ 0., 41., 82., 123., 164., 205., 246., 287., 328., 369., 410.])
vectorize與otypes:
In [48]: np.vectorize(F,otypes=[float])(x)
Out[48]:
array([0. , 0.1025, 0.205 , 0.25 , 0.25 , 0.2625, 0.365 , 0.4675,
0.82 , 0.9225, 1.0 ])
和使用串列理解同樣的事情:
In [49]: np.array([F(i) for i in x])
Out[49]:
array([0. , 0.1025, 0.205 , 0.25 , 0.25 , 0.2625, 0.365 , 0.4675,
0.82 , 0.9225, 1.0 ])
對于這么小x,串列理解更快;對于你的大x_range,vectorize更快。
“真正矢量化”的計算是:
def foo(x):
res = np.zeros(x.shape)
mask = (x>0) & (x<=100); res[mask] = 0.0025*x[mask]
mask = (x>100) & (x<=200); res[mask] = .25
mask = (x>200) & (x<=300); res[mask] = 0.0025*x[mask]-.25
mask = (x>300) & (x<=400); res[mask] = 0.0025*x[mask]
mask = (x>400); res[mask] = 1
return res
對于我的 10 元素x來說速度較慢,但??對于大x_range尺度來說要好得多。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/428941.html
標籤:Python 麻木的 matplotlib
上一篇:RESTDjango-如何在將序列化檔案放入模型之前對其進行修改
下一篇:熱圖上的中心顏色條標簽