我有一個CSV檔案,型別如下:
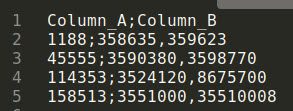
我需要將其重新格式化為以下形式:
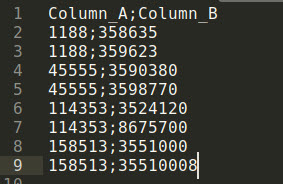
你能告訴我,如何將 columnColumn_B劃分為行,但只能Column_A根據 column 填充相應的值Column_B。
非常感謝。
uj5u.com熱心網友回復:
我建議df.explode()在修改Column_B為list-type 后利用:
df = pd.read_csv(text, sep=';')
df['Column_B'] = df['Column_B'].str.split(',')
df = df.explode('Column_B')
df.to_csv('test.csv', sep=';', index=False)
uj5u.com熱心網友回復:
首先,您需要將 CSV 檔案內容檢索為原始文本。
content = "..."
final_content = ""
# a readable solution
for line in content.split('\n'):
key = line.split(';')[0]
vals = line.split(';')[1].split(',')
final_content = key ";" vals[0] "\n"
final_content = key ";" vals[1] "\n"
相同的解決方案,但看起來更短
final_content = "\n".join([line.split(';')[0] ":"line.split(';')[1].split(",")[0] '\n' line.split(';')[0] ":"line.split(';')[1].split(",")[1] for line in content.split('\n')])
uj5u.com熱心網友回復:
基本上,您需要拆分行并從一行中創建這兩行。這是一步一步的解決方案:(我用我的變數名解釋了它)
with open('old.csv') as f:
# storing the header
header = next(f)
res = []
for line in f:
with_semicolon_part, without_semicolumn_part = line.rstrip().split(',')
first_part, second_part = with_semicolon_part.split(';')
lst = [first_part, second_part, without_semicolumn_part]
res.append(lst)
# creating new csv file with our `res`.
with open('new.csv', mode='w') as f:
f.write(header)
for lst in res:
f.write(lst[0] ';' lst[1] '\n')
f.write(lst[0] ';' lst[2] '\n')
uj5u.com熱心網友回復:
import pandas as pd
import numpy as np
df = pd.read_csv(<"fname.csv">, sep=";")
df = pd.DataFrame(np.repeat(df.values, 2, axis=0), columns=df.columns)
df.iloc[1::2,1] = df.iloc[1::2,1].str.replace(".*,", "", regex=True)
df.iloc[::2,1] = df.iloc[::2,1].str.replace(",.*", "", regex=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/429204.html
標籤:Python python-3.x
下一篇:變數的索引分配