資料可在以下網址找到:https ://www.kaggle.com/tovarischsukhov/southparklines
SP = read.csv("/Users/michael/Desktop/stat 479 proj data/All-seasons.csv")
SP$Season = as.numeric(SP$Season)
SP$Episode = as.numeric(SP$Episode)
Clean.Boys = SP %>% select(Season, Episode, Character) %>%
arrange(Season, Episode, Character) %>%
filter(Character == "Kenny" | Character == "Cartman") %>%
group_by(Season, Episode)
count = table(Clean.Boys)
count = as.data.frame(count)
Clean = count %>% pivot_wider(names_from = Character, values_from = Freq) %>% group_by(Episode)
Season Episode Cartman Kenny
<fct> <fct> <int> <int>
1 1 1 85 5
2 2 1 1 0
3 3 1 43 19
4 4 1 83 6
5 5 1 37 3
6 6 1 67 0
我正在嘗試使用 ggplot 制作一個帶有 2 條線的圖,一條用于 Cartman 變數,一條用于 Kenny 變數。我的兩個問題是
我的資料格式是否正確以使用 geom_line() 繪制圖?還是我必須將其旋轉更長的時間?
我想將 X 比例繪制為連續變數,類似于日期,但它是季節和劇集。例如,第一個繪圖點是第 1 季第 1 集,然后是第 1 季第 2 集,依此類推。我被困在如何將季節和劇集放在不同的列中來做到這一點,即使我將它們結合起來,我也不確定正確的格式是什么。
uj5u.com熱心網友回復:
在此示例中,我習慣于readr::read_csv讀取檔案并在呼叫中設定變數型別,以將其保存在單獨的代碼行中。
頻率計數可以dplyr::summarise在管道作業流中使用 , 完成。
我不確定您希望將季節和劇集資料保留為連續變數的真正含義 - 您必須更明確地說明您希望它的外觀。我采用的方法是提供一種使用最少文本顯示季節和劇集的方法:默認情況下,季節和劇集的順序是數字順序,但是當組合成一個字符時,它們必須通過使用強制轉換為數字順序factor。另一種選擇可能是按季節分面。
ggplot 喜歡長格式的資料,所以不需要將資料轉換成寬格式。
為了保持圖表的可讀性,僅顯示前 80 個觀察值。
library(readr)
library(dplyr)
library(ggplot2
SP <- read_csv("...your file path.../All-seasons.csv"col_types = "nncc")
Clean.Boys <-
SP %>%
select(-Line) %>%
arrange(Season, Episode, Character) %>%
filter(Character == "Kenny" | Character == "Cartman") %>%
group_by(Season, Episode, Character)%>%
summarise(count = n(), .groups = "keep") %>%
mutate(x_lab = factor(paste(Season, Episode, sep = "\n"))) %>%
head(n = 80)
ggplot(Clean.Boys)
geom_line(aes(x_lab, count, group = Character, colour = Character))
labs(x = "Season and episode")
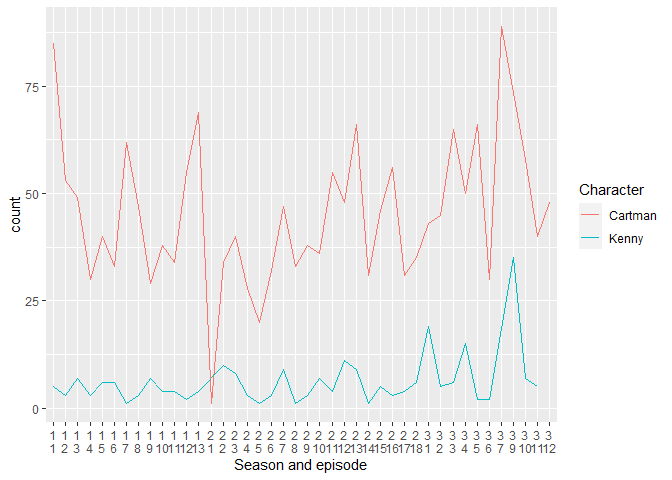
由reprex 包于 2022-02-20 創建(v2.0.1)
uj5u.com熱心網友回復:
訣竅是將要映射的列收集為變數。我不知道,你想如何繪制你的圖表,意思是關于 x 軸和 y 軸,我做了一個偽圖。對于您的連續變數部分,您可以使用as.integer()or將您的值轉換為整數或數字as.numeric(),然后您可以將其用作連續刻度。你可以通過呼叫來檢查你的變數結構str(df),它將顯示你的變數的類,如果它是因子或字符,將它們轉換為數字。
#libraries
library(ggplot2)
#> Warning: package 'ggplot2' was built under R version 4.0.5
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(tidyr)
#> Warning: package 'tidyr' was built under R version 4.0.3
#your code
SP <- read.csv("C:/Users/saura/Desktop/All-seasons.csv")
SP$Season = as.numeric(SP$Season)
#> Warning: NAs introduced by coercion
SP$Episode = as.numeric(SP$Episode)
#> Warning: NAs introduced by coercion
Clean.Boys = SP %>% select(Season, Episode, Character) %>%
arrange(Season, Episode, Character) %>%
filter(Character == "Kenny" | Character == "Cartman") %>%
group_by(Season, Episode)
count = table(Clean.Boys)
count = as.data.frame(count)
Clean = count %>% pivot_wider(names_from = Character, values_from = Freq) %>% group_by(Episode)
#here is your code, but as I dont know, what you want on your axis
new_df <- Clean %>%
gather(-Season,-Episode, key = "Views", value = "numbers")
ggplot(data = new_df, aes(
as.numeric(Episode),
numbers,
color = Views,
group = Views
))
geom_path()
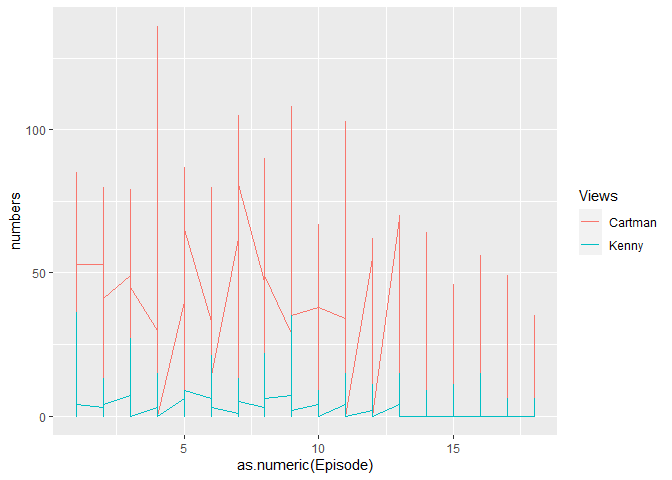
由reprex 包(v2.0.1)創建于 2022-02-19
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/429482.html
上一篇:向地圖添加連續/漸變填充