我正在嘗試使用 BeautifulSoup 并請求將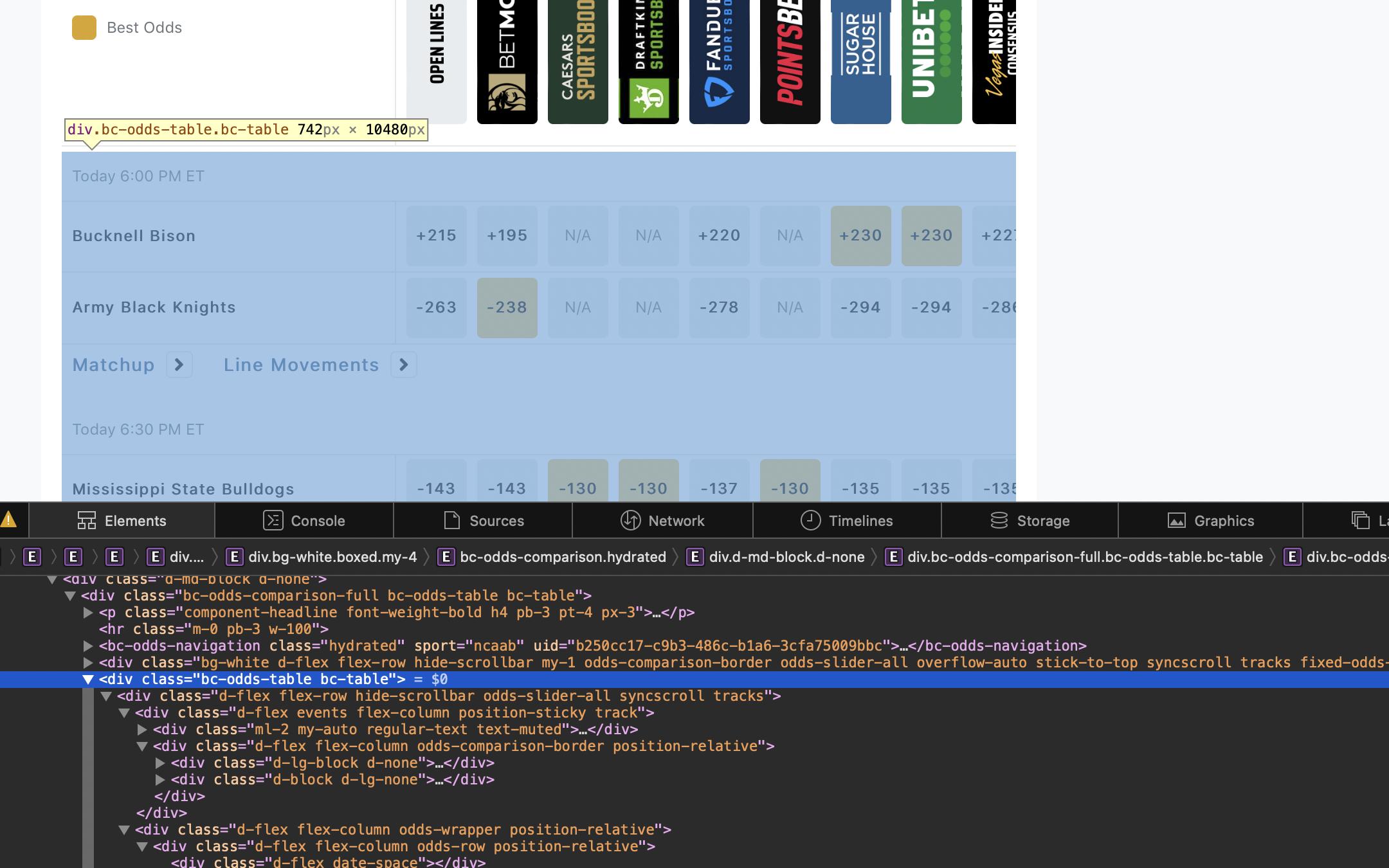
我也可以通過這樣做得到一些東西:
data = [[x.text for x in y.findAll('div')] for y in divList]
df = pd.DataFrame(data)
print(df)
[1 rows x 5282 columns]
我如何能夠遍歷這些 div 并在 pandas 資料框中回傳資料?
使用 div.text 時,它會回傳我想要的一長串資料。我可以把這個字串分成很多塊,然后把它粘到我想要它去的 df 中。但這似乎充其量只是一項黑客作業。
uj5u.com熱心網友回復:
您基本上需要通過識別類名中的唯一識別符號來遍歷所有 div。嘗試這個:
import pandas as pd
import requests
from bs4 import BeautifulSoup
def extract_data_from_div(div):
# contains the names of the teams
left_side_div = div.find('div', class_='d-flex flex-column odds-comparison-border position-relative')
name_data = []
for name in left_side_div.find_all('div', class_='team-stats-box'):
name_data.append(name.text.strip())
# to save all the extracted odds
odds = []
# now isolate the divs with the odds
for row in div.find_all('div', class_='px-1'):
# all the divs for each bookmaker
odds_boxes = row.find_all('div', class_='odds-box')
odds_box_data = []
for odds_box in odds_boxes:
# sometimes they're just 'N/A' so this will stop the code breaking
try:
pt_2 = odds_box.find('div', class_='pt-2').text.strip()
except:
pt_2 = ''
try:
pt_1 = odds_box.find('div', class_='pt-1').text.strip()
except:
pt_1 = ''
odds_box_data.append((pt_2, pt_1))
# append to the odds list
odds.append(odds_box_data)
# put the names and the odds together
extracted_data = dict(zip(name_data, odds))
return extracted_data
url = "https://www.vegasinsider.com/college-basketball/odds/las-vegas/"
resp = requests.get(url)
soup = BeautifulSoup(str(resp.text), "html.parser")
# this will give you a list of each set of match odds
div_list = soup.find_all('div', class_='d-flex flex-row hide-scrollbar odds-slider-all syncscroll tracks')
data = {}
for div in div_list:
extracted = extract_data_from_div(div)
data = {**data, **extracted}
# finally convert to a dataframe
df = pd.DataFrame.from_dict(data, orient='index').reset_index()
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/431737.html