我正在使用以下網站: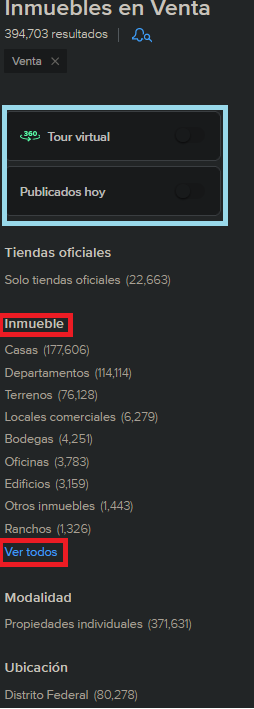
如下圖所示,這些類ui-search-filter-dl包含上圖選單中的特定部分;而ui-search-filter-container類包含站點顯示的子部分(例如 Inmueble 的 Casas、Departamento 和 Terrenos)。為了從“Inmueble”部分的“ver todos”按鈕獲取鏈接,我使用了這行代碼:
ver_todos = response.css('div.ui-search-filter-dl')[2].css('a.ui-search-modal__link').attrib['href']
但由于“Tour virtual”和“Publicados hoy”并不總是在頁面中,我不能確定ui-search-filter-dl在索引 2 處總是對應于“ver todos”按鈕的索引。
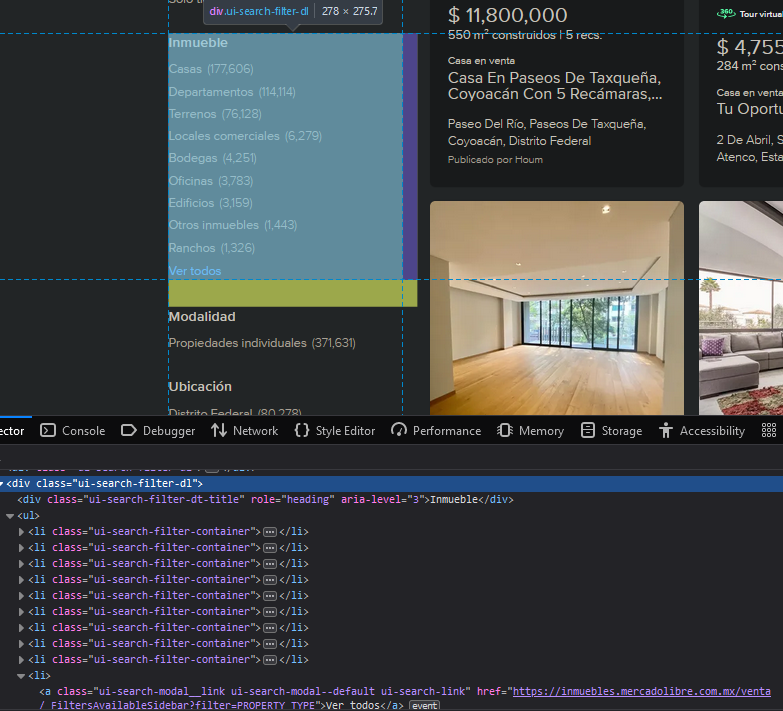
我試圖通過使用這行代碼從“ver todos”獲取鏈接:
response.css(''':contains("Inmueble") ~ .ui-search-filter-dt-title
.ui-search-modal__link::attr(href)''').extract()
基本上,我試圖從ui-search-filter-dt-title包含標題“Inmueble”的類中獲取 href。不幸的是,輸出是一個空串列。我想通過使用 css 和正則運算式從“ver todos”中找到鏈接,但我遇到了麻煩。我怎樣才能做到這一點?
uj5u.com熱心網友回復:
我認為 xpath 在大多數情況下更容易選擇目標元素:
代碼:
xpath = "//div[contains(text(), 'Inmueble')]/following-sibling::ul//a[contains(@class,'ui-search-modal__link')]/@href"
url = response.xpath(xpath).extract()[0]
實際上,我并沒有創建一個scrapy 專案來檢查您的代碼。或者,我實作了以下代碼:
from lxml import html
import requests
res = requests.get( "https://inmuebles.mercadolibre.com.mx/venta/")
dom = html.fromstring(res.text)
xpath = "//div[contains(text(), 'Inmueble')]/following-sibling::ul//a[contains(@class,'ui-search-modal__link')]/@href"
url = dom.xpath(xpath)[0]
assert url == 'https://inmuebles.mercadolibre.com.mx/venta/_FiltersAvailableSidebar?filter=PROPERTY_TYPE'
由于scrapy和lxml中的xpath應該是一樣的,當然,我希望開頭顯示的代碼在你的scrapy專案中也能正常作業。
uj5u.com熱心網友回復:
一個簡單的方法是獲取所有鏈接<a>,然后檢查是否有任何文本匹配ver todos。
import requests
from bs4 import BeautifulSoup
link = "https://inmuebles.mercadolibre.com.mx/venta/"
def main():
res = requests.get(link)
if res.status_code == 200:
soup = BeautifulSoup(res.text, "html.parser")
links = [a["href"] for a in soup.select("a") if a.text.strip().lower() == "ver todos"]
print(links)
if __name__ == "__main__":
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/431744.html