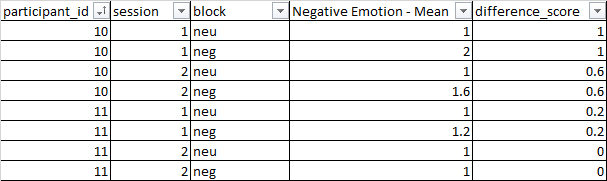
我需要計算“負面情緒 - 平均值”列中的 2 個單元格之間的差異分數,“參與者 ID”和“會話”列中的值相同。差異分數是 block=neg 減去 block=neu 我的預期輸出顯示在“difference_score”列中
在不建立字典的情況下,我怎樣才能做到熊貓?
預先感謝!
uj5u.com熱心網友回復:
更簡單的方法是將 ID 列設定為索引并使用掩碼:
df2 = df.set_index(['participant_id', 'session'])
mask = df2['block'].eq('neg')
df2['difference_score'] = df2.loc[mask, 'Negative Emotions - Mean']-df2.loc[~mask, 'Negative Emotions - Mean']
df2.reset_index()
由于資料是影像,因此未提供輸出。
uj5u.com熱心網友回復:
一種方法是利用 pandaspandas.DataFrame.groupby和pandas.DataFrame.groupby.GroupBy.apply函式。
Groupby 根據指定的列對您的 DataFrame 進行分組,然后應用運行您通過 GroupBy 物件傳遞的任何函式。
所以,首先,讓我們制定你想做的邏輯,首先,你想按參與者id和會話分組,然后你想得到neg的值,neu的值,然后放置將此差異放入一個名為 difference_score 的新列中。
# This function will get the difference from the grouped rows.
def get_score_difference(rows: pd.DataFrame):
# Get neg value in a try catch block, ensuring neg is defaulted to 0 if not in df
try:
neg = rows.loc[rows['block'] == 'neg']['Negative Emotion - Mean'][0]
except Exception as e:
neg = 0
# Get neu value in the same fashion as neg
try:
neu = rows.loc[rows['block'] == 'neu']['Negative Emotion - Mean'][0]
except Exception as e:
neu = 0
# Add new column with neg - neu
rows['difference_score'] = neg - neu
# Return new rows
return rows
# Apply the function to the dataframe
df.groupby(['participant_id', 'session']).apply(get_score_difference)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/433540.html
標籤:Python 熊猫 数据框 熊猫-groupby 区别