如圖所示,我有 pandas df
Name Subject Score
Rakesh Math 65
Mukesh Science 76
Bhavesh French 87
Rakesh Science 88
Rakesh Hindi 76
Sanjay English 66
Mukesh English 98
Mukesh Marathi 77
我必須制作另一個 df,包括參加兩個或更多科目的學生,并在每個科目中合計他們的分數。
因此,結果 df 將如下所示:
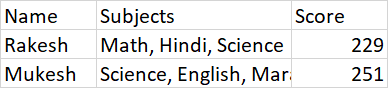
uj5u.com熱心網友回復:
在 pandas 中,有一種方法explode可以獲取包含串列的列并將它們分開。我們可以通過列出您的主題列來做與此相反的事情。我從另一個問題中提取了這個想法。
In [1]: df = df.groupby('Name').agg({'Subject': lambda x: x.tolist(), 'Score':'sum'})
In [2]: df
Out[2]:
Subject Score
Name
Bhavesh [French] 87
Mukesh [Science, English, Marathi] 251
Rakesh [Math, Science, Hindi] 229
Sanjay [English] 66
然后,我們可以過濾Subject串列中包含多個專案的任何行的列。我從另一個SO question 提出的這種方法。
In [3]: df[df['Subject'].str.len() > 1]
Out[3]:
Subject Score
Name
Mukesh [Science, English, Marathi] 251
Rakesh [Math, Science, Hindi] 229
如果您希望該Subject列是一個字串而不是一個串列,您可以使用來自 SO 的第三個其他答案。
df['Subject'] = df['Subject'].apply(lambda x: ", ".join(x))
uj5u.com熱心網友回復:
使用groupby,我們可以在一行中完成filter:agg
(df.groupby('Name')
.filter(lambda g:len(g)>1)
.groupby('Name')
.agg({'Subject': ', '.join, 'Score':'sum'})
)
輸出
Subject Score
Name
Mukesh Science, English, Marathi 251
Rakesh Math, Science, Hindi 229
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/433559.html
上一篇:按資料幀中的最大值和最小值過濾
下一篇:使用分隔符將一列拆分為多列