- 作業系統:Windows 10
- 蟒蛇:3.7.11
- IDE:jupyter筆記本
我有一個包含以下四列的資料集:bug_report_number, class_id, time_stamp, label. 資料集如下所示:
41737 120098 1583149803 0
41737 120116 1583149803 0
41737 120136 1583149803 0
41748 120179 1583135020 0
41748 120177 1583135020 -1
41748 120177 1583135020 -1
41754 120177 1583135020 1
41754 120200 1583135020 0
41754 120188 1583135020 0
我想分組bug_report_number,然后檢查class_id該錯誤報告的列值是否唯一。
例如,對于41748bug_report_number 我希望得到False,對于41754我希望得到True.
我寫的代碼如下:
import pandas as pd
train_file_path = "dataset_hbase - v.03.csv"
columns_name = ["bug_report_number", "class_id", "time_stamp", "label"]
columns_dtype = {0: "int64", 1: "int64", 2: "int64", 3:"int64"}
df = pd.read_csv(train_file_path, header=None, names=columns_name, dtype=columns_dtype)
temp = df.groupby(["bug_report_number"])
temp["class_id"].is_unique
但是當我使用.is_unique它時回傳以下錯誤:
AttributeError: 'SeriesGroupBy' object has no attribute 'is_unique'
題:
- 如何分組
bug_report_number然后檢查class_id該錯誤報告的列值是否唯一?
uj5u.com熱心網友回復:
采用:
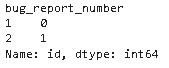
data = pd.DataFrame({'bug_report_number': [1,2,1,2,1], 'id': [50,35,50,30,50]})
df = pd.DataFrame(data)
df.groupby('bug_report_number')['id'].apply(lambda x: 0 if len(list(x))==len(set(x)) else 1)
輸出:
uj5u.com熱心網友回復:
IIUC,你可以使用groupby nunique。eq(1)這個想法是計算每個“bug_report_number”的唯一“class_id”的數量,如果它等于 1,則回傳 True,否則回傳 False。
s = df.groupby('bug_report_number')['class_id'].nunique()
out = s.eq(1)
輸出:
bug_report_number
41737 False
41748 False
41754 False
Name: class_id, dtype: bool
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/433563.html