我正在使用一個小資料集與熊貓一起作業,但我被困在某個地方。
合并后的資料如下:
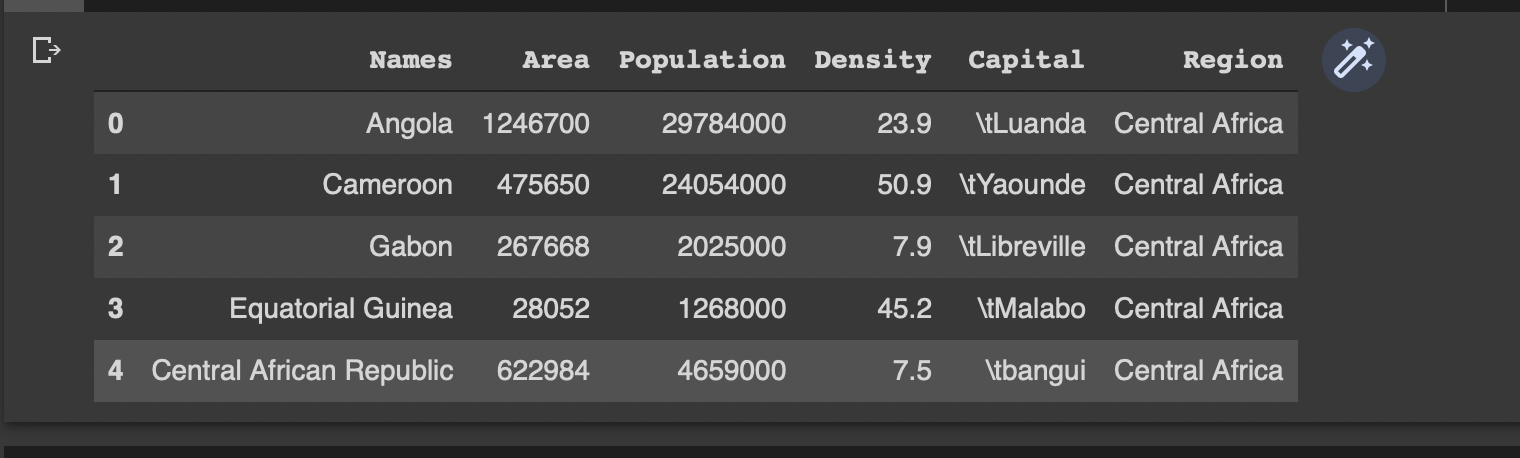
使用這些資料,下面的代碼給出了每個區域的最小面積,并在獲得的 Dataframe 的同一行上加上相應的國家名稱。
Area_min=Africa.groupby('Region').Area.agg([min])
Area_min['Country']=(Africa.loc[Africa.groupby('Region').Area.idxmin(), 'Names']).values
Area_min
而這一項給出了每個地區的最大人口,并在獲得的Dataframe中的同一行上填寫了相應的國家名稱。
Pop_max=Africa.groupby('Region').Population.agg([max])
Pop_max['Country']=(Africa.loc[Africa.groupby('Region').Population.idxmax(), 'Names']).values
Pop_max
現在,我正在嘗試獲取每個地區的平均人口,并在獲得的資料框中的同一行上填寫人口最接近相應組平均值的國家名稱。
下面的代碼給出了每個地區的平均人口,但我堅持與國家名稱相對應。
Pop_average=Africa.groupby('Region').Population.agg(['mean'])
我正在考慮 .map() 和 .apply() 函式,但我嘗試過但沒有成功。任何提示都會有所幫助。
uj5u.com熱心網友回復:
由于您僅按一列分組,因此執行一次效率更高。
此外,由于您idxmin無論如何都在使用,因此執行 first 似乎是多余的groupby.agg,因為您可以直接訪問列名。
g = Africa.groupby('Region')
Area_min = Africa.loc[g['Area'].idxmin(), ['Names', 'Area']]
Pop_max = Africa.loc[g['Population'].idxmax(), ['Names', 'Population']]
那么對于您的問題,這是一種方法。變換總體mean并找到均值和總體之間的差值,并使用abs groupby 找到差值最小的位置idxmin;然后使用loc上面的訪問器來獲得所需的結果:
Pop_average = Africa.loc[((g['Population'].transform('mean') - Africa['Population']).abs()
.groupby(Africa['Region']).idxmin()),
['Names','Population']]
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/433575.html
標籤:Python 熊猫 数据框 熊猫-groupby 系列
上一篇:根據比較規則更改列值
下一篇:lapply串列中資料框中的列名