我正在嘗試從同一架構的 Impala 中獲取單個表/視圖串列的總列數。
但是我想掃描該架構中的所有表以捕獲單個查詢中的列?
我已經從 Oracle Exadata 執行了類似的練習,但是由于我是 Impala 的新手,有沒有辦法捕獲?
我使用的 Oracle Exadata 查詢
select owner, table_name as view_name, count(*) as counts
from dba_tab_cols /*DBA_TABLES_COLUMNS*/
where (owner, table_name) in
(
select owner, view_name
from dba_views /*DBA_VIEWS*/
where 1=1
and owner='DESIRED_SCHEMA_NAME'
)
group by owner ,table_name
order by counts desc;
黑斑羚
uj5u.com熱心網友回復:
在 Hive v.3.0 及更高版本中,您INFORMATION_SCHEMA可以從 Hue 查詢 db 以獲取所需的列資訊。
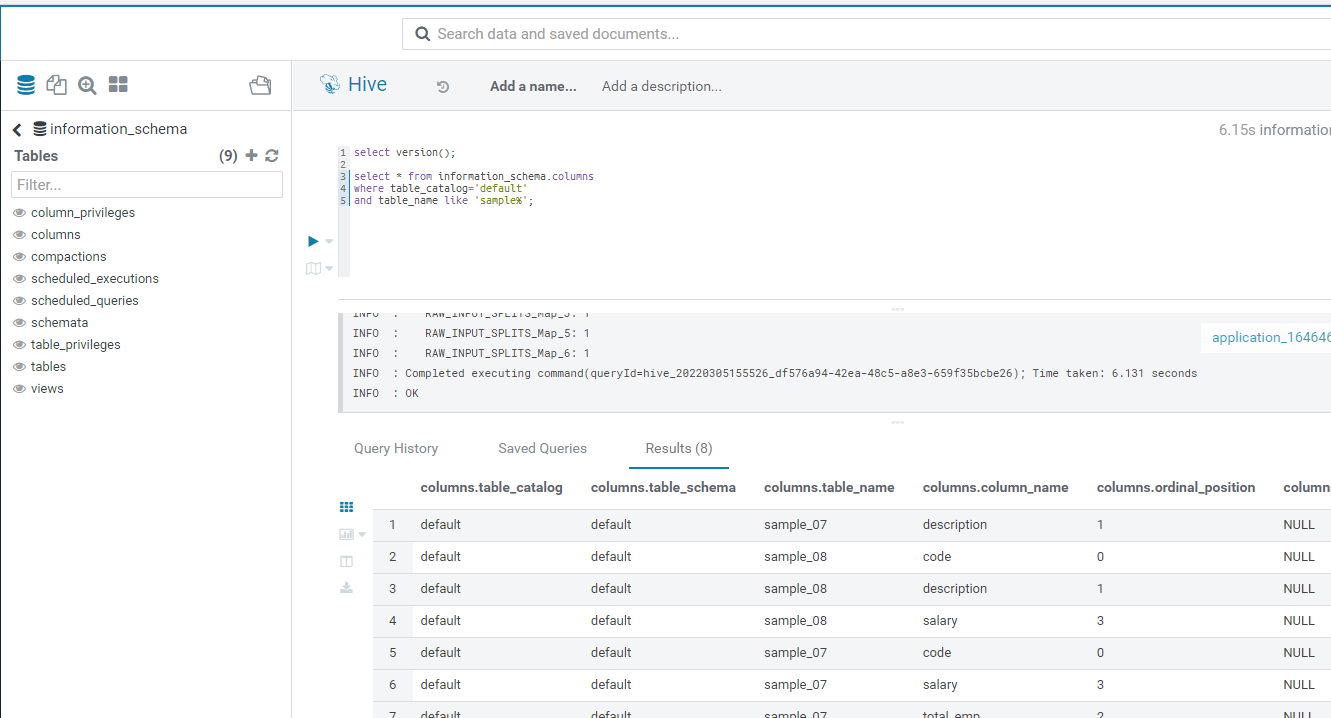
Impala 仍然落后,JIRA IMPALA-554在 Impala 中實作 INFORMATION_SCHEMA和 IMPALA-1761 仍未解決。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/440130.html
標籤:Hadoop 蜂巢 黑斑羚 cloudera-cdh
上一篇:使用獨立的YARN運行spark集群(不使用Hadoop的YARN)
下一篇:為什么提交表單時陣列不更新