我想獲取此網頁每一行的“data-id”值。
我復制了第一行的 XPath,但是,它只是從第一行列印 x 次“data-id”的值。預期結果應該是每行的資料 ID 列印出自己的資料 ID
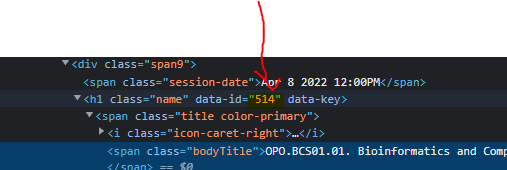
預期輸出 - “514” “515” “516” ... ...
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.abstractsonline.com/pp8/#!/10517/sessions/@timeSlot=Apr08/1')
page_source = driver.page_source
element = driver.find_elements_by_xpath('.//li[@]')
for el in element:
id=el.find_element_by_xpath('/html/body/div[1]/div[2]/div/div/div[2]/div[2]/div/div[2]/div[2]/ul/li[1]/div[1]/div[1]/h1').get_attribute("data-id")
print(id)
uj5u.com熱心網友回復:
嘗試這樣的事情:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.abstractsonline.com/pp8/#!/10517/sessions/@timeSlot=Apr08/1')
//page_source = driver.page_source
element = driver.find_elements_by_xpath('.//li[@]//h1')
for el in element:
id=el.get_attribute("data-id")
print(id)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/440563.html