所以我有一個包含“A”、“B”、“C”、“D”列的資料框。
我想要一個包含 c(A,B,C,D) 的列 df$Vector。
例如,如果資料像
Name A B C D
1 0.5 0.7 0.6 0.9
2. 0.4 0.8 0.3 0.1
3 0.5 0.9. 0.1 0.2
然后 df$Vector 會像
Name Vector
1 c(0.5,0.7,0.6,0.9)
2 c(0.4,0.8,0.3,0.1)
3 c(0.5,0.9,0.1,0.2)
我嘗試使用 df$Vector <- list(c(df$A...df$D) 使串列包含所有值,而不是與該行相關的值。有人有什么想法嗎?
uj5u.com熱心網友回復:
transpose()從data.table:_
df$vector = as.list(data.table::transpose(df[-1]))
df[2:5] <- NULL
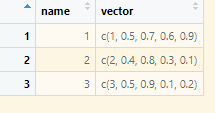
name vector
1 1 1.0, 0.5, 0.7, 0.6, 0.9
2 2 2.0, 0.4, 0.8, 0.3, 0.1
3 3 3.0, 0.5, 0.9, 0.1, 0.2
可重現的資料:
df = data.frame(
name = 1:3,
A = c(0.5, 0.4, 0.5), B = c(0.7, 0.8, 0.9),
C = c(0.6, 0.3, 0.1), D = c(0.9, 0.1, 0.2)
)
uj5u.com熱心網友回復:
你可以這樣做:
df$Vector <- lapply(seq(nrow(df)), function(x) c(df[x,]))
df <- df[c(1, 6)]
這給了你
df
#> Name Vector
#> 1 1 1.0, 0.5, 0.7, 0.6, 0.9
#> 2 2 2.0, 0.4, 0.8, 0.3, 0.1
#> 3 3 3.0, 0.5, 0.9, 0.1, 0.2
uj5u.com熱心網友回復:
可以這樣做:
library(tidyr)
library(dplyr)
library(purrr)
nest(df, -Name) %>%
mutate(
data = map(data, unlist, use.names = F)
) %>%
rename(Vector = data)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/441262.html
上一篇:重新編碼R中的現有列
下一篇:在資料幀R中拆分值