我有以下資料框:
| 2級 | 3級 | 開始日期 | 日期結束 |
|---|---|---|---|
| 月刊 | 1 | 2022-01-01 | 2022-01-01 |
| 月刊 | 2 | 2022-01-01 | 2022-01-01 |
| 月刊 | 5 | 2022-01-01 | 2022-01-01 |
| 半年 | H1 | 2022-01-01 | 2022-01-01 |
| 半年 | H2 | 2022-01-01 | 2022-01-01 |
| 季刊 | 第一季度 | 2022-01-01 | 2022-01-01 |
| 季刊 | 第三季度 | 2022-01-01 | 2022-01-01 |
| 季刊 | 第四季度 | 2022-01-01 | 2022-01-01 |
最初,所有 'DateStart' 和 'DateEnd' 日期時間默認設定為 2022-01-01,我需要根據 Level2 和 Level3 列調整它們。我可以使用 df.iterrows() 成功地做到這一點,但是腳本需要很長時間才能運行,因為有數十萬行。這是我的代碼:
for i, row in df.iterrows():
if df.loc[i, 'Level2'] == 'Monthly':
df.loc[i, 'DateStart'] = df.loc[i, 'DateStart'] relativedelta(months = int(df['Level3'][i]) - 1)
df.loc[i, 'DateEnd'] = df.loc[i, 'DateStart'] relativedelta(months = 1, days=-1)
elif df.loc[i, 'Level2'] == 'Quarterly':
df.loc[i, 'DateStart'] = df.loc[i, 'DateStart'] relativedelta(months = (int(df['Level3'][i][-1]) * 3) - 3)
df.loc[i, 'DateEnd'] = df.loc[i, 'DateStart'] relativedelta(months = 3, days=-1)
elif df.loc[i, 'Level2'] == 'Semi-annual':
df.loc[i, 'DateStart'] = df.loc[i, 'DateStart'] relativedelta(months = (int(df['Level3'][i][-1]) * 6) - 6)
df.loc[i, 'DateEnd'] = df.loc[i, 'DateStart'] relativedelta(months = 6, days=-1)
else:
df.loc[i, 'DateEnd'] = df.loc[i, 'DateStart'] relativedelta(years=1, days=-1)
這就是我們在這種情況下需要的結果:
| 2級 | 3級 | 開始日期 | 日期結束 |
|---|---|---|---|
| 月刊 | 1 | 2022-01-01 | 2022-01-31 |
| 月刊 | 2 | 2022-02-01 | 2022-02-28 |
| 月刊 | 5 | 2022-05-01 | 2022-05-31 |
| 半年 | H1 | 2022-01-01 | 2022-06-30 |
| 半年 | H2 | 2022-07-01 | 2022-12-31 |
| 季刊 | 第一季度 | 2022-01-01 | 2022-03-31 |
| 季刊 | 第三季度 | 2022-07-01 | 2022-09-30 |
| 季刊 | 第四季度 | 2022-10-01 | 2022-12-31 |
任何幫助將不勝感激,以使這個程序更快
uj5u.com熱心網友回復:
幾點觀察:
“Level2”列是多余的,因為“Level3”中的值區分不同的周期長度。
StartDate 只有 12 4 2=18 個可能的值,EndDate 也是如此。
因此,最簡單的方法是預先計算 StartDate 和 EndDate 的所有 18 個可能值,并將它們存盤在一個字典中。
然后使用:
df[“StartDate”] = df[“Level3”].map(start_dict)
df[“EndDate”] = df[“Level3”].map(end_dict)
----
編輯:盡管您的問題指出所有日期都在 2022 年,但您上面的評論表明并非如此。在這種情況下,您需要構建一個增量字典,而不是最終日期。然后使用 map() 如上所示,最后將這些增量添加到開始日期列。
uj5u.com熱心網友回復:
你可以試試這個解決方案:
start_date = {"Q1":"1","Q2":"4","Q3":"7","Q4":"10","H1":"1","H":"7"}
end_date = {"Q1":"3","Q2":"6","Q3":"9","Q4":"12","H1":"6","H":"12"}
df["DateStart"] = df["Level 3"]
df["DateStart"] = "2022-" df["DateStart"].replace(start_date)
df["DateStart"] = pd.to_datetime(df["DateStart"], format='%Y-%m')
df["DateEnd"] = df["Level 3"]
df["DateEnd"] = "2022-" df["DateEnd"].replace(end_date)
df["DateEnd"] = pd.to_datetime(df["DateEnd"], format='%Y-%m') pd.offsets.MonthEnd(0)
如果有,您可以將“2022-”替換為您的列年份。有了這些資料:
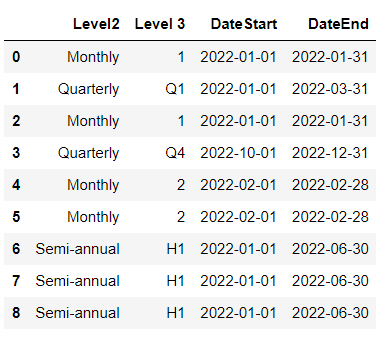
import pandas as pd
import numpy as np
data = {
'Level2': ['Monthly', 'Quarterly', 'Monthly', 'Quarterly', 'Monthly', 'Monthly', 'Semi-annual', 'Semi-annual', 'Semi-annual'],
'Level 3': ['1', 'Q1', '1', 'Q4', '2', '2', 'H1', 'H1', 'H1'],
'DateStart': ['2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01'],
'DateEnd': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-01', '2022-01-02', '2022-01-03', '2022-01-01', '2022-05-02', '2022-06-30']
}
df = pd.DataFrame(data)
輸出
uj5u.com熱心網友回復:
你可以使用 pandas 的 groupby 函式,然后進行聚合。
import pandas as pd
import numpy as np
data = {
'Level2': ['Monthly', 'Monthly', 'Monthly', 'Monthly', 'Monthly', 'Monthly', 'Semi-annual', 'Semi-annual', 'Semi-annual'],
'Level 3': ['1', '1', '1', '2', '2', '2', 'H1', 'H1', 'H1'],
'DateStart': ['2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01', '2022-01-01'],
'DateEnd': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-01', '2022-01-02', '2022-01-03', '2022-01-01', '2022-05-02', '2022-06-30']
}
df = pd.DataFrame(data)
df_grouped = df.groupby(['Level2', 'Level 3'])
df_res = df_grouped.agg({'DateStart': np.min, 'DateEnd': np.max})
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/441266.html
上一篇:如何使第一個索引列為空?