我有兩個 DataFrame A 和 B as-
table_a = pd.DataFrame({
'unique_id':[3823762,3976695,4199277,4201777,4202712],
'full_name':['A','B','C','D','E'],
'freq_match_it':[np.NaN,np.NaN,np.NaN,np.NaN,np.NaN],
'address':['hyd','jgl','krmr','wl','ktk']
})
table_b = pd.DataFrame({
'unique_id':[419434,4201777,784744,4202712,10000],
'freq_match_it':[12,15,8,5,100]
})
在這里,我想填寫在 pandas 中使用左連接時存在的freq_match_it列table_aunique_idtable_b
pd.merge(table_a,table_b,how='left',on='unique_id')
它顯示為-

在這里它創建了一個額外的列freq_match_it_y,我想填寫已經存在的列freq_match_it而不是創建一個額外的列。
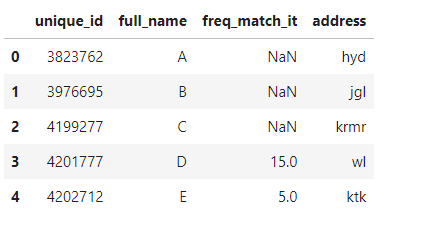
預期的輸出是
uj5u.com熱心網友回復:
Series.fillna通過將第二個 DataFrame 中的 Series 映射為and來替換缺失值Series.map:
s = table_b.set_index('unique_id')['freq_match_it']
table_a['freq_match_it'] = table_a['freq_match_it'].fillna(table_a['unique_id'].map(s))
uj5u.com熱心網友回復:
你可以map:
table_a['freq_match_it'] = table_a['unique_id'].map(table_b.set_index('unique_id')['freq_match_it'])
輸出:
unique_id full_name freq_match_it address
0 3823762 A NaN hyd
1 3976695 B NaN jgl
2 4199277 C NaN krmr
3 4201777 D 15.0 wl
4 4202712 E 5.0 ktk
uj5u.com熱心網友回復:
您快到了,合并并使用后綴,然后根據后綴名稱或包含所有 NaN 的列洗掉。不需要其他地方提出的多重計算
pd.merge(table_a,table_b,how='left',on='unique_id', suffixes=('_x','')).dropna(axis=1,how='all')
unique_id full_name address freq_match_it
0 3823762 A hyd NaN
1 3976695 B jgl NaN
2 4199277 C krmr NaN
3 4201777 D wl 15.0
4 4202712 E ktk 5.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/441278.html
上一篇:如何檢查在LangDetect中產生LangDetectException錯誤的哪一行?
下一篇:通過R中的選定組隨機化樣本