我有一個資料框如下。
df_add = pd.DataFrame({
'unique_id':['a-1','a-2','a-3','a-4','a-5'],
'doc_id':[100,101,102,103,104],
'last_name':['Fernando','Fernando','Samba','Bhavik','Bhavik'],
'first_name':['Reich','Reich','Anil','Reich','Reich'],
'dob':['06-03-1900','06-03-1900','20-09-2020','09-16-2020','01-01-2021'],
'health':['Yes','','Yes','','Yes']
})
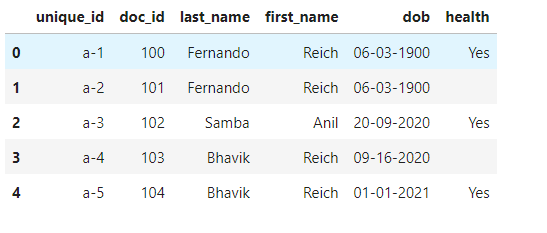
我們可以看到,考慮到 last_name 和 first_name,有兩個人的記錄是重復的,如下所示。
- 費爾南多·賴希 (Fernando Reich) 與出生日期“06-03-1900”相同
- Bhavik Reich 有兩個不同的出生日期,分別是“09-16-2020”和“01-01-2021”
如果 last_name 的重復組合和這些行的第一次匯總應使用分號分隔符完成,例如:
情況1:
a-1 和 a-2 記錄在姓氏和名字上重復,因此應將其匯總并記錄為一個。
Dob 被認為是唯一的,因為它存在于兩條記錄中。
a-1;a2 | 100;101 |費爾南多 |帝國 |06-03-1900| 是的
案例二:
a-4 和 a-5 記錄在姓氏和名字上重復,它應該是一個記錄。此人的 DOB 不同,因此用 ; 分隔。
a-4;a-5 |103;104 |Bhavik |Reich |09-16-2020;01-01-201 |是
這里這個任務的目標是洗掉重復并減少資料幀的行數,這是預期的輸出。
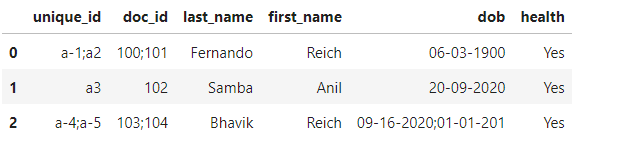
您可以看到 5 行匯總為 3 行。
uj5u.com熱心網友回復:
您可以使用GroupBy.agg:
# function to aggregate as joined string without duplicates
# and maintaining original order
agg = lambda x: ';'.join(dict.fromkeys(map(str,x)))
out = (df_add
.groupby(['last_name', 'first_name'], as_index=False)
.agg({'unique_id': agg, 'doc_id': agg, 'dob': agg, 'health': 'max'})
)
輸出:
last_name first_name unique_id doc_id dob health
0 Bhavik Reich a-4;a-5 103;104 09-16-2020;01-01-2021 Yes
1 Fernando Reich a-1;a-2 100;101 06-03-1900 Yes
2 Samba Anil a-3 102 20-09-2020 Yes
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/446226.html