我一直在玩 cut 并指定特定的 bin 大小,但有時我的 bin 中的資料不正確。
我想要做的是根據它在我的風險影響矩陣中的位置來分類資料。
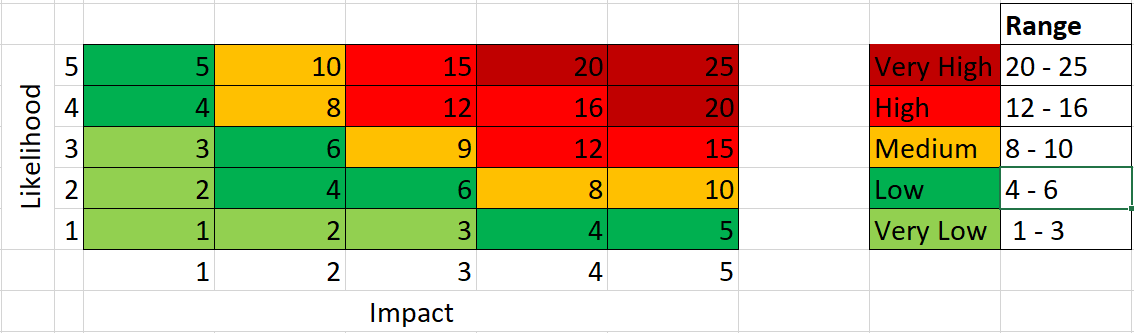
下面是我用來創建我的 dataFrame 并分配我的 bin 和標簽的原始代碼。
risk = {'Gross Risk': {0: 1, 1: 3, 2: 4, 3: 6, 4: 9, 5: 14, 6: 20, 7: 5, 8: 8, 9: 16, 10: 22, 11: 1, 12: 3, 13: 6, 14: 9, 15: 12, 16: 25}}
df = pd.DataFrame.from_dict(risk)
# Create a list of names we will call the bins
group_names = ['Very Low', 'Low', 'Medium', 'High', 'Very High']
# Specify our bin boundaries
evaluation_bins = [1, 4, 8, 12, 20, 25]
# And stitch it all together
df['Risk Evaluation'] = pd.cut(df['Gross Risk'], bins = evaluation_bins, labels = group_names, include_lowest = True)
這將創建以下輸出
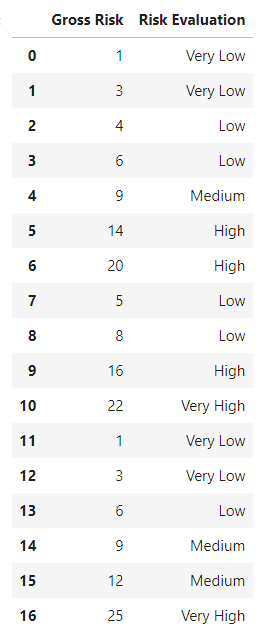
對照我的風險矩陣檢查這一點,我可以看到第 6、7、8 和 15 行被錯誤地隔離了。
為了解決這個問題,我重新指定了 Evaluation_Bins 資料。我沒有采用 bin 的下限,而是指定了上限。
evaluation_bins = [1, 3, 6, 10, 16, 25]
這給了我想要的結果。但要么我從根本上誤解了如何指定 Pandas 切割邊界,我認為我必須指定下限,而不是更高,或者我只是僥幸獲得了我想要的結果。
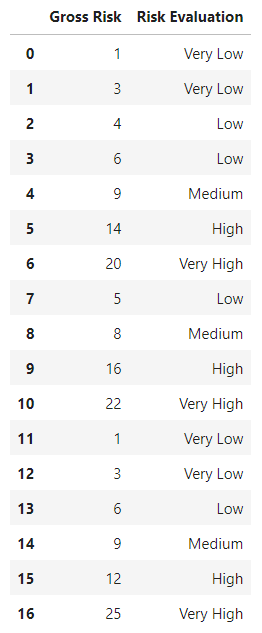
有人可以讓我放心,讓我知道我是否錯過了解固定寬度垃圾箱的創建如何作業?
對人好點 :)
uj5u.com熱心網友回復:
更改evaluation_bins并right=False用作 的引數pd.cut:
evaluation_bins = [1, 4, 8, 12, 20, np.inf]
df['Risk Evaluation2'] = pd.cut(df['Gross Risk'], bins=evaluation_bins,
labels=group_names, include_lowest=True, right=False)
print(df)
# Output
Gross Risk Risk Evaluation Risk Evaluation2
0 1 Very Low Very Low
1 3 Very Low Very Low
2 4 Very Low Low
3 6 Low Low
4 9 Medium Medium
5 14 High High
6 20 High Very High
7 5 Low Low
8 8 Low Medium
9 16 High High
10 22 Very High Very High
11 1 Very Low Very Low
12 3 Very Low Very Low
13 6 Low Low
14 9 Medium Medium
15 12 Medium High
16 25 Very High Very High
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/446238.html
上一篇:從groupby轉換生成資料幀