我正在按照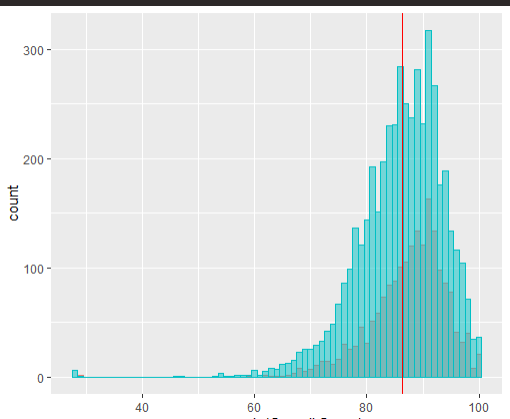
你有什么建議嗎?
uj5u.com熱心網友回復:
除了前面的建議,你還可以使用單獨存盤的組均值,即兩個而不是 nrow=1000 高度冗余的值:
## a 'tidy' (of several valid ways for groupwise calculation):
group_means <- df %>%
group_by(group) %>%
summarise(group_means = mean(x, na.rm = TRUE)) %>%
pull(group_means)
## ... ggplot code ...
geom_vline(xintercept = group_means)
uj5u.com熱心網友回復:
我會計算資料框中的平均值:
library(ggplot2)
library(dplyr)
df %>%
group_by(group) %>%
mutate(mean_x = mean(x))
輸出是:
# A tibble: 1,000 × 3
# Groups: group [2]
x group mean_x
<dbl> <chr> <dbl>
1 -0.962 G1 0.0525
2 -0.293 G1 0.0525
3 0.259 G1 0.0525
4 -1.15 G1 0.0525
5 0.196 G1 0.0525
6 0.0301 G1 0.0525
7 0.0854 G1 0.0525
8 1.12 G1 0.0525
9 -1.22 G1 0.0525
10 1.27 G1 0.0525
# … with 990 more rows
這樣做:
library(ggplot2)
library(dplyr)
df %>%
group_by(group) %>%
mutate(mean_x = mean(x)) %>%
ggplot(aes(x, fill = group, colour = group))
geom_histogram(alpha = 0.5, position = "identity")
geom_vline(aes(xintercept = mean_x), col = "red")
輸出是:
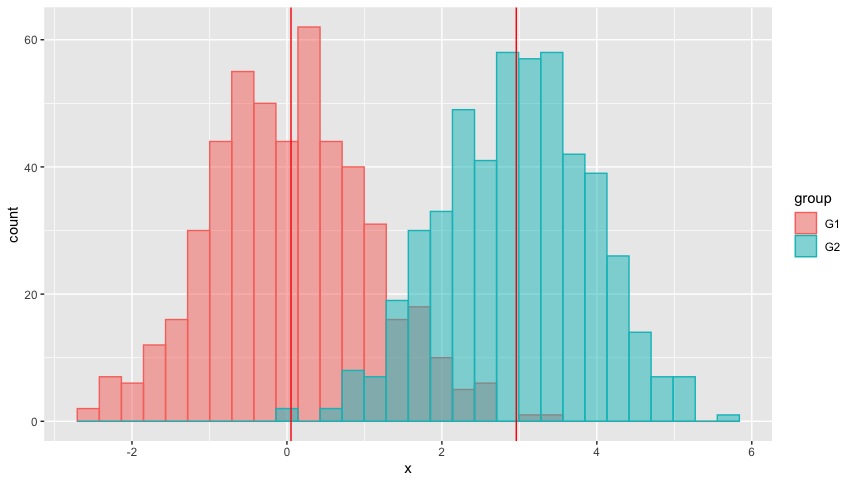
uj5u.com熱心網友回復:
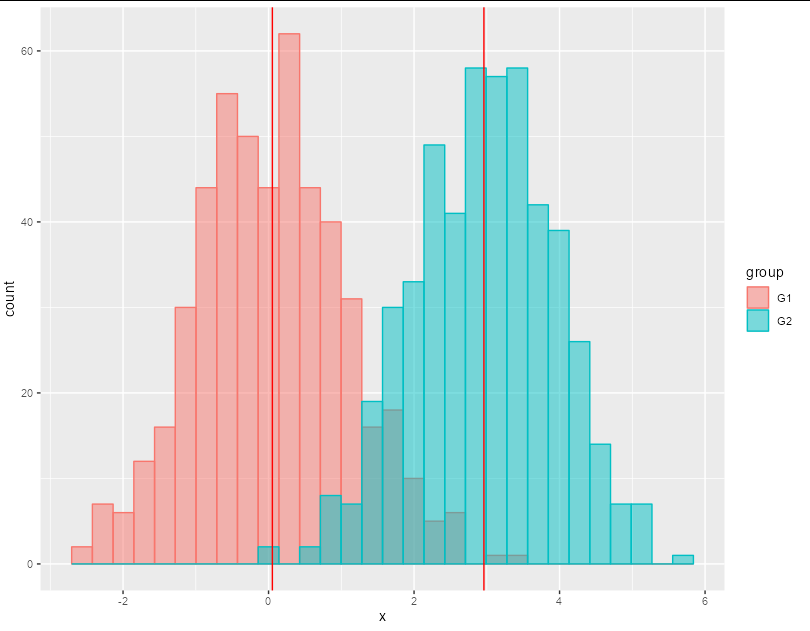
沒有預計算的簡單方法是:
ggplot(df, aes(x = x, fill = group, colour = group))
geom_histogram(alpha = 0.5, position = "identity")
geom_vline(xintercept = tapply(df$x, df$group, mean), col = "red")
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/452271.html