對于給定的系統字庫(可以通過注冊表獲取對應的檔案名稱),給定一個系統字庫名和一個Unicode代碼(包括4位元組CJK-B/C/D/E/F區的漢字),需要解決:
1. 字庫是否存在;
2. 該字庫存在的風格(Bold, Italic等等);
3. 該字符在字庫檔案中是否存在(Regular或Reguaular不存在則Bold,其中一種即可);
4. 字符存在時字形(Glyph)資料是否存在(非空白);
5. 字形存在時獲取該字形對應的所有Unicode編碼(一個字形可以對應多個Unicode編碼)。
前面4專案前是可以通過API做到的,最后一項找不到頭緒,請大俠幫忙,可以有償獲取原始碼(請加QQ商議),但需要將上面所有內容封裝到一個VB類,如能同時提供VB.NET(2005或2008)可用則更好。
QQ: 616139, 請備注。
uj5u.com熱心網友回復:
其實最簡單的就是picturebox font屬性加載這個字體,然后用你要測驗的unicode在picturebox上print一下,然后再來檢查picturebox上還有沒有前景色變化。如果有,判定為該字模存在。沒有,一片空白,說明沒有這個字模。uj5u.com熱心網友回復:
百度搜“字體檔案 一個字形對應多個Unicode”
uj5u.com熱心網友回復:
不太像是編程式uj5u.com熱心網友回復:
老師,我是真的找不到,沒有這樣的帖子,API也看不出端倪uj5u.com熱心網友回復:
https://msdn.microsoft.com/en-us/library/windows/desktop/dd144821(v=vs.85).aspxhttps://msdn.microsoft.com/en-us/library/windows/desktop/dd144819(v=vs.85).aspx
uj5u.com熱心網友回復:
10遍……

uj5u.com熱心網友回復:
編程式檢查picture是否變了不算編程式?只要能達到目的,介意用什么姿勢么?干掉敵人一定要用規定的武器么?拿花盆砸死他或者把他按在馬桶里淹死就不算是消滅敵人么。
好吧,前面那個回復只是解決你的第4問。
一定要用正統的方式的話,你的第5問我覺得應該是找不到現成API的(當然,可能是我不知道),因為字體的使用都是用unicode去檢索出圖元資料(glyf),然后顯示出來。用圖元反推unicode這個應用場景我沒有想到,至于用圖元反推指向其的多個不同unicode,我承認,我覺得這個應用場景有點匪夷所思。
如果這事情讓我來做,基本上就是直接決議ttf檔案來處理了。ttf檔案中的 CMAP表記錄的是Character to Glyph Index Mapping Table 也就是字符到圖元的對應關系。如果有你所說的多個unicode對應同一個圖元的情況,那么在這個Mapping Table里面應該可以找到多個相同的圖元地址偏移。我的想法是先把索引對照表根據圖元地址進行排序,然后從第一個開始往下擼,當遇到前后圖元地址相同的,那么就是找到你想要的了。并且不止兩個的話都是聚集在一起的,繼續往下擼,直到出現前后不一致的地方就是這一批相同字模的資料結尾。繼續往下擼看看還有沒有別的……
具體的,還是看檔案吧:
https://docs.microsoft.com/zh-cn/typography/opentype/spec/cmap
反正這個檔案我沒看完……
后來又找到這個
https://www.cnblogs.com/sjhrun2001/archive/2010/01/19/1651274.html
應該會更好理解一點吧。
uj5u.com熱心網友回復:
要處理比較多的字串,用繪圖的方式是不行的,最關鍵還是要解決多映射的問題,微軟的資料看起來比較有用,謝謝!uj5u.com熱心網友回復:
難道就沒有圖元地址不同,對應的Unicode也不同,但圖元對應的實際幾何形狀完全相同的字符?
uj5u.com熱心網友回復:
首先,這種情況屬于做字庫的人腦袋有坑,并不是每個腦洞,我們都必須去適應。
其次,這種情況當然屬于兩個不同的字,只是看上去一樣而已,看上去一樣就是一樣么?
uj5u.com熱心網友回復:
用戶、甲方、雇主說看上去一樣就是一樣;碼農、乙方、雇員說看上去一樣不一定是一樣,顯然沒用。
uj5u.com熱心網友回復:
趙4 現在可以發言了?又開始亂說了…………

uj5u.com熱心網友回復:
才消停兩天,帶著一堆人的群嘲居然能申訴回來
uj5u.com熱心網友回復:
唉!謝謝你們的關心!首先,我不是為了要學習這種技術,而是想在一個專案中解決這個問題,以前不是特別了解,不太可能花很多時間來做研究;其次,這個問題的提出只是為了使程式看起來更友好一點,稍微給使用者省點事,其實,對字庫有研究的人做一個這樣的模塊比我肯定要省事很多,所以我也愿意給付一定的報酬;其三,一開始我覺得就描述清楚了,主要是第五條。
uj5u.com熱心網友回復:
說風涼話湊熱鬧是我的專長。
uj5u.com熱心網友回復:
5. 字形存在時獲取該字形對應的所有Unicode編碼(一個字形可以對應多個Unicode編碼)。其中“該字形”
既可以理解為字體檔案中某個唯一確定的字形資料的起始地址;
也可以理解為所有和該字形的幾何形狀沒區別的字形。
uj5u.com熱心網友回復:
https://www.baidu.com/link?url=LODX47rs9UOEpgMnsaHJp4ENFPNg_eTTNnfOWyqNqe-AI70ydoPbRDHln20VmMSUuuZFmdMZBUdczikf_Y9AZa&wd=&eqid=9ac0ebb4000237eb000000025b331e62
uj5u.com熱心網友回復:
這次改版之后,文字“加粗”了,反正我在瀏覽器中看到的“字”(字)和“宇”(宇)是一樣的。
uj5u.com熱心網友回復:
為了不產生無意義的抬杠,發一個有多個unicode對應一個字模的字庫案例出來唄。uj5u.com熱心網友回復:
http://www.keshou.top/downloads/jdfmk.ttf
這個字庫是一個繁體字庫,為了使輸入簡體字不會產生缺失(通常顯示框),因此將簡體和繁體做了部分映射(盡量無歧義的漢字),所以,比如“萬(4E07)”和“萬(842C)”就是同一個字形的映射,很顯然,也不是所謂字形識別的問題,這樣的字形修改之后,兩個Unicode內碼對應的字形都變了。
當然,獲取一個字形對應的Unicode的用途不是這么小范圍,比如,對于4位元組漢字(CJK-B/C/D/E/F)而言,要映射到很多應用程式可以使用的雙位元組,通常要靠造字(不要跟我討論修改字體來顯示的問題,事實上目前的控制元件絕大部分不支持雙字體或者備用字體模式),只是不是要造一個字形,只是要從專用區給一個編碼,這樣,標準4位元組到底對應哪個雙位元組編碼,通過字庫來查找對照關系顯然比使用一個對照表要簡單,也有更好的使用體驗。
uj5u.com熱心網友回復:
第五點,基本上是沒有現成API可以給你用的了,所以個人覺得只能直接從ttf檔案著手分析,在8樓我就說了我的初步想法是利用CMAP去找重復字模。樓主發出來ttf檔案了,那么就拿這個案例嘗試分析一下檔案,通過檔案資料的查看,看看我的想法是否可行。先看看https://docs.microsoft.com/zh-cn/typography/opentype/spec/otff
這里面描述了檔案頭的一些結構
我們開UE直接看這個tff檔案的資料。約定一下,接下來我們所說的涉及資料地址和檔案內具體的數值一切都是16進制表達,懶得進行數值轉換了,而且具體的數值在UE截圖上也很容易找到。
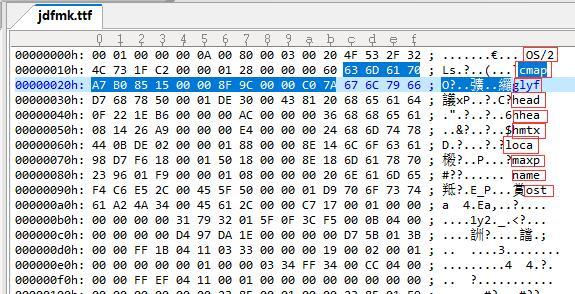
根據ttf的資料結構定義。檔案最前面是一個TableDirectory結構,12個位元組。1~4是固定版本號 緊接著是兩個位元組,說有幾個表,這里看是0A也就是說有10張表。從后面我用紅框框出來的表名看的確有10個表。
其他的我們都不是很關心,直接看CMAP表的資訊。也就是從 1C~2B的16個位元組圖中我選起來的部分。 這是一個TableEntry結構,1~4位元組是表名 5~8是checksum 9~12是偏移地址,13~16是表長度。從資料看,偏移在8F9C 長度是C07A
那么我們就直奔8F9C而去
接下來我們看微軟的cmap檔案
https://docs.microsoft.com/zh-cn/typography/opentype/spec/cmap
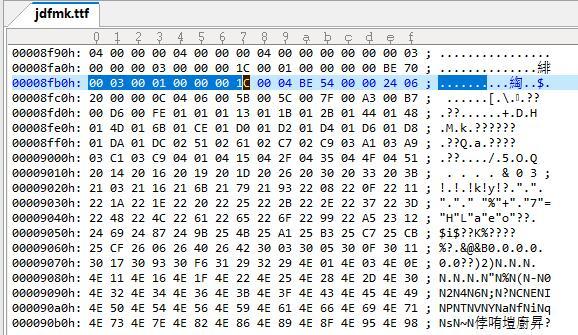
先是'cmap' Header結構,4個位元組,1~2是cmap版本固定為0。3~4是子表數目。這里我們看到子表數目的偏移地址再 8F9E~8F9F這里顯示的是03,也就是有3個子表。
那么接下來就是3個EncodingRecord 結構,這種結構8個位元組 是1~2位元組為Platform ID 平臺ID,3~4為平臺自己的special ID 5~8為子表起始位置偏移。
序號 Platform ID Platform-specific encoding ID 偏移
1 00 03 1C
2 01 00 BE70
3 03 01 1C
接著看檔案 查表,平臺ID 00 為unicode 01為Macintosh我們可以不管 03是windows。 繼續擼檔案,windows平臺強烈建議(strongly recommends)用unicode表,實際上這個字庫的Platform-specific encoding ID的確也是 01 Unicode BMP。 所以我們可以看到這個字體庫里 子表1 和2 偏移是一樣的,都指向同一個表。
麥金托什的咱不管了,專心看unicode的這張表。它的偏移是1C,也就是十進制的28。這個偏移是相對于CMAP的起始位置的偏移,也就是從 8F9C + 1C 開始是子表資料的開始。 這個1C其實也就是 一個4位元組的cmap Header結構,加上3個8位元組的 EncodingRecord 總共28個位元組。
接下來就比較復雜了,cmap的資料格式有7種,檔案中明確:Fonts that support Unicode BMP characters on the Windows platform must have a format 4 'cmap' subtable for platform ID 3, platform-specific encoding 1.
所以我們繼續往下擼檔案,看format4的資料結構。
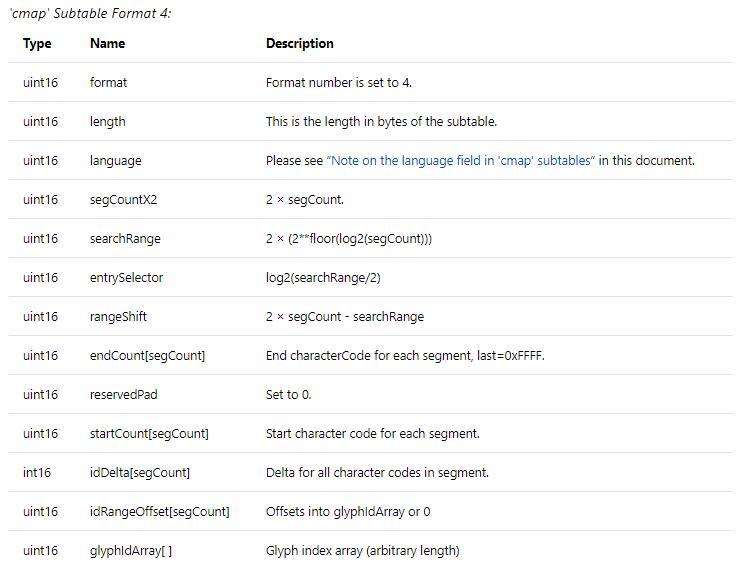
Format 4 是雙位元組編碼。這種格式用于字體檔案中的編碼分布與幾個連續的區域,在區域之間可能有一些保留的空白。而有一些編碼可能并不會與字體中的glyph對應。2位元組的壓縮編碼則使用format6。
表頭開始是格式編號format、子表長度length及語言language。緊接著是format資料。它分為3個部分:
4 word(UInt16)的頭部,指定用于加快分段表查找的引數。
4個陣列,用于描述段(段是一個連續的編碼范圍)。
glyphID陣列
所以,我們要判定是否有重復的的字模,只要看 glyphID陣列里面有沒有重復的資料,然后反推出其對應的unicode就行了
第一步,先取得glyphID陣列,無非就是算地址偏移。format4里有endCount[segCount]、startCount[segCount]、idDelta[segCount]、idRangeOffset[segCount] 這4個陣列,這4個陣列的尺寸其實就都是segCountX2這個欄位的值(每個陣列有segCount個元素,每個元素是一個uint16也就是2個位元組,所以每個陣列的尺寸就是segCount * 2個位元組)。
好,剛才我們已經算出,cmap第一張圖子表的起始地址是8F9C + 1C = 8FB8。先看一下這里開始的1~2位元組,數值為04 , 檔案顯示format4的前兩個位元組固定值為4,說明到目前為止看上去還沒有數錯。 我們要的segCountX2在 7~8位元組 值為 2406 數一下format4的結構,在glyphID陣列前,一共有8個uint16欄位和剛才說的4個陣列。所以這些資訊一共有 2*8+4*2406 = 9028 (這些全是16進制計算哈) 那么 glyphID陣列的起始位置就是 8FB8 + 9028 = 11FE0
到這個地址看看資料情況:
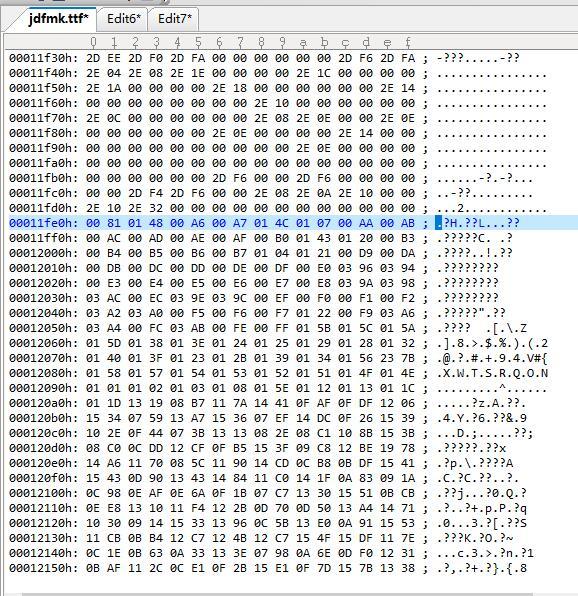
很明顯,這個地址的前后資料結構明顯不同,說明咱基本沒算錯。然后就是取出整個陣列,然后找出陣列的重復項。這塊就要代碼實作,看UE截圖沒用了。至于這個陣列的結尾在哪里,對于這個字庫檔案,可以投機取巧,因為就兩個表,麥金托什表的起始位置是 8F9C + BE70 ,那么這個地址的前一個位元組就是glyphID陣列的結尾。算出來glyphID陣列的長度應該是2E2B 。如果是最后一個表,應該要按 TableEntry結構里的對CMAP表長度的描述進行計算。
如果找到重復的glyphID,說明你找到了重復的字模了,那么接下來就是根據format4的資訊反推UNICODE了
先要了解正推的演算法,具體的演算法可以看檔案中format4結構下面的那一大段。
寫到這里戛然而止,一是下班時間到了,二是正推演算法我也還沒看明白。待看明白以后再來吧。

uj5u.com熱心網友回復:
樓上高手,分析得不錯嘛。
晚上有空再繼續…………

uj5u.com熱心網友回復:
CMAP的中文版見:http://www.bubfun.com/post/2018/06/30/ttfe69687e4bbb6e4b8adCMAPe8a1a8e7bb93e69e84.aspx
uj5u.com熱心網友回復:
哎,覺得東西在大腦里面已經接近完整了,但是缺乏一個驗證,但驗證就要寫代碼,想想寫代碼就要把前面擼的文字再換成代碼,都有點不想折騰了。而且,目前只看了format4 ,如果遇到其他的format又要重新來了uj5u.com熱心網友回復:
你這是“趕在時代的前列”啊……


uj5u.com熱心網友回復:
哦,沒調整博客的時區
uj5u.com熱心網友回復:
有沒有興趣把這個模塊做出來呀,你那么熟,可以省很多事。至于平臺ID的問題,大概是4種,Windows 和 Unicode 各兩種,一個只支持雙位元組,一個支持4位元組,主要是要解決4位元組編碼到雙字編碼的映射關系uj5u.com熱心網友回復:
不熟啊,這也是第一次擼字體檔案的檔案。4位元組怎么對應我也不知道啊,也要再去找其他檔案
uj5u.com熱心網友回復:
可以先嘗試做做雙位元組的,但是 1、不保證成功 2、不保證時間 3、我做私活價格不低有興趣私聊 QQ:71429660
uj5u.com熱心網友回復:
一會字庫、一會字形。。。沒明白啥意思。。。
字庫,字體檔案?
字形,字體檔案中對應的字符?
unicode編碼會根據字體不同而改變?
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/45292.html
標籤:API
下一篇:課程設計