我有一個這樣的資料框,
data = {'first_column': ['first_sentence', 'second_sentence'], 'second_column': ['A', 'B'], 'third_column' : ['C', 'D'] }
原來的結構是這樣的
第一列 第二列 第三列
first_sentence AC
second_sentence BD
我想把它轉換成以下格式
first_column 列
first_sentence A
first_sentence C
second_sentence B
second_sentence D
我試過了df.stack()
但它給了
0 first_column first_sentence
second_column A
第三列 C
1 first_column second_sentence
第二列 B
第三列 D
我在原始資料框中有大約 27 列,我想生成 1 列,我該怎么做
先感謝您。
uj5u.com熱心網友回復:
嘗試使用melt:
pd.melt(df, id_vars=['first_column'], value_vars=['second_column', 'third_column'], value_name='column')
.sort_values(by="first_column").drop(['variable'], axis=1)
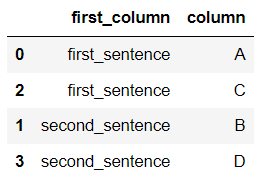
uj5u.com熱心網友回復:
set_index之前使用stack:
out= df.set_index('first_column').stack().droplevel(1).rename('column').reset_index()
print(out)
# Output
first_column column
0 first_sentence A
1 first_sentence C
2 second_sentence B
3 second_sentence D
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/453431.html
標籤:python-3.x 熊猫 数据框