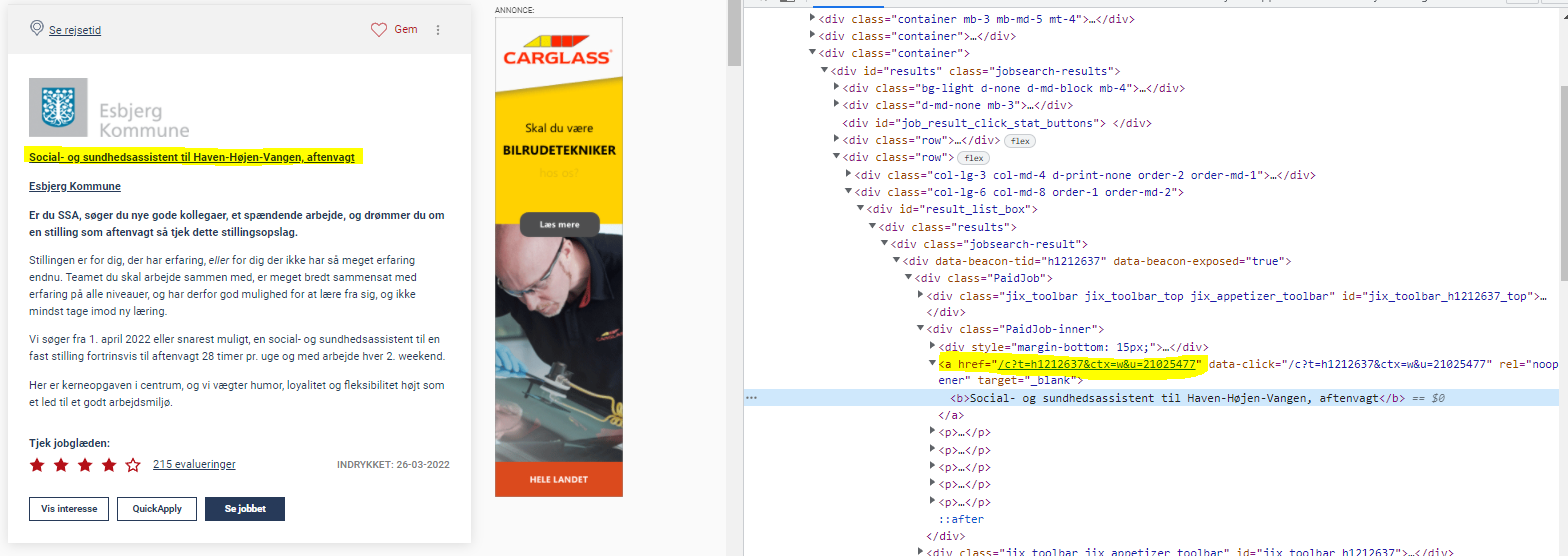
到目前為止,我已經創建了以下代碼來提取所有資訊,但我不知道如何提取鏈接。我嘗試過使用 for 回圈,但我得到了不同的鏈接。我真的希望有人能指出我正確的方向。
def extract(page, tag):
url = f"https://www.jobindex.dk/jobsoegning?page ={page} &q ={tag}"
r = requests.get(url, headers)
soup = BeautifulSoup(r.content.decode("utf-8"), "html.parser")
return soup
def transform(soup):
divs = soup.find_all("div", class_="jobsearch-result")
for item in divs:
title = item.find_all("b")[0].text.strip()
company = item.find_all("b")[1].text.strip()
published_date = item.find("time").text.strip()
summary = item.find_all("p")[1].text.strip()
job_location = item.find_all("p")[0].text.strip()
job_url = item.find_all("href")
job = {
"title" : title,
"company" : company,
"published_date" : published_date,
"summary" : summary,
"job_location" : job_location,
"Job_url" : job_url
}
joblist.append(job)
return
uj5u.com熱心網友回復:
您可以將屬性 = 值 css 選擇器與包含*運算子組合到子字串的目標onclick屬性。添加到該選擇器串列:has以指定具有匹配onclick屬性的元素必須具有直接子b標簽,該標簽將匹配限制為具有粗體職位的那些
[data-click*="u="]:has(> b)
import requests
from bs4 import BeautifulSoup
def extract(page, tag):
headers = {'User-Agent':'Mozilla/5.0'}
url = f"https://www.jobindex.dk/jobsoegning?page={page}&q={tag}"
r = requests.get(url, headers)
soup = BeautifulSoup(r.content.decode("utf-8"), "html.parser")
return soup
def transform(soup):
divs = soup.find_all("div", class_="jobsearch-result")
for item in divs:
title = item.find_all("b")[0].text.strip()
company = item.find_all("b")[1].text.strip()
published_date = item.find("time").text.strip()
summary = item.find_all("p")[1].text.strip()
job_location = item.find_all("p")[0].text.strip()
job_url = item.select_one('[data-click*="u="]:has(> b)')['href']
job = {
"title" : title,
"company" : company,
"published_date" : published_date,
"summary" : summary,
"job_location" : job_location,
"Job_url" : job_url
}
joblist.append(job)
return
joblist = []
soup = extract(1, "python")
#print(soup)
transform(soup)
print(joblist)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/454895.html
上一篇:字串太長時正則運算式不起作用?