II 目前有一個非常大的 .csv,有 200 萬行。我已經閱讀了 csv 并且只有 2 列,數字和時間戳(在 unix 中)。我的目標是獲取每天的最后一個和最大的數字(例如 2021 年 1 月 1 日、2021 年 1 月 2 日等)
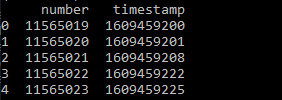
我已將 unix 轉換為 datetime 并使用 df.groupby('timestamp').tail(1) 但仍然無法回傳每天的最后一行。我使用 groupby 錯了嗎?
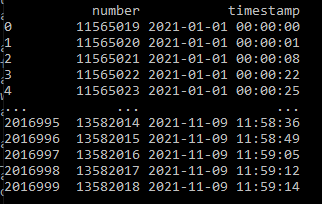
import pandas as pd
def main():
df = pd.read_csv('blocks.csv', usecols=['number', 'timestamp'])
print(df.head())
df['timestamp'] = pd.to_datetime(df['timestamp'],unit='s')
x = df.groupby('timestamp').tail(1)
print(x)
if __name__ == '__main__':
main()
期望的輸出:
數字時間戳
11,509,218 2021-01-01
11,629,315 2021-01-02
11,782,116 2021-01-03
12,321,123 2021-01-04
...
uj5u.com熱心網友回復:
“問題”在于 grouper,.dt.date用于正確分組(假設您的資料已經排序):
x = df.groupby(df['timestamp'].dt.date).tail(1)
print(x)
uj5u.com熱心網友回復:
似乎您沒有指定聚合函式,也沒有指定聚合頻率(小時、天、分鐘?)我的看法類似于
df.resample("D", on="timestamp").max()
有幾種按時間分組的方法,或者
df.groupby(pd.Grouper(key='timestamp', axis=0,
freq='D', sort=True)).max()
問候
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/455766.html
標籤:Python 熊猫 数据框 约会时间 熊猫-groupby
上一篇:選擇.groupby()之外的列