我想檢索下面影像的所有輪廓,但忽略文本。
圖片:

當我嘗試找到當前影像的輪廓時,我得到以下資訊:
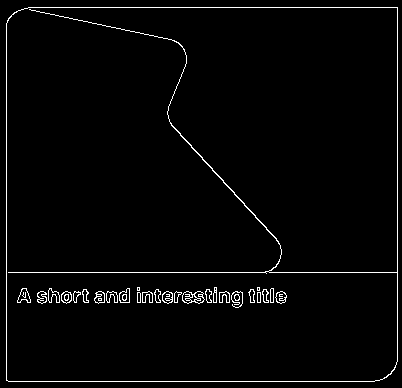
我不知道該怎么做,因為我是使用 OpenCV 和影像處理的新手。我想忽略文本,我該如何實作?如果忽略是不可能的,但在文本周圍制作一個邊界框,那也很好。
編輯:
我需要匹配的標準:
- 輪廓的大小和形狀可能非常大。
- 圖片中的顏色可能會有所不同。
- 圖片中文字的顏色和大小可能會有所不同。
uj5u.com熱心網友回復:
這是在 Python/OpenCV 中執行此操作的一種方法。
- 讀取輸入
- 轉換為灰度
- 獲得 Canny 邊緣
- 應用形態關閉以確保它們關閉
- 獲取所有輪廓層次結構
- 過濾輪廓以僅在周長中保留高于閾值的輪廓
- 在輸入上繪制輪廓
- 在黑色背景上繪制每個輪廓
- 保存結果
輸入:

import numpy as np
import cv2
# read input
img = cv2.imread('short_title.png')
# convert to gray
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# get canny edges
edges = cv2.Canny(gray, 1, 50)
# apply morphology close to ensure they are closed
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3,3))
edges = cv2.morphologyEx(edges, cv2.MORPH_CLOSE, kernel)
# get contours
contours = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours = contours[0] if len(contours) == 2 else contours[1]
# filter contours to keep only large ones
result = img.copy()
i = 1
for c in contours:
perimeter = cv2.arcLength(c, True)
if perimeter > 500:
cv2.drawContours(result, c, -1, (0,0,255), 1)
contour_img = np.zeros_like(img, dtype=np.uint8)
cv2.drawContours(contour_img, c, -1, (0,0,255), 1)
cv2.imwrite("short_title_contour_{0}.jpg".format(i),contour_img)
i = i 1
# save results
cv2.imwrite("short_title_gray.jpg", gray)
cv2.imwrite("short_title_edges.jpg", edges)
cv2.imwrite("short_title_contours.jpg", result)
# show images
cv2.imshow("gray", gray)
cv2.imshow("edges", edges)
cv2.imshow("result", result)
cv2.waitKey(0)
灰度:

邊緣:

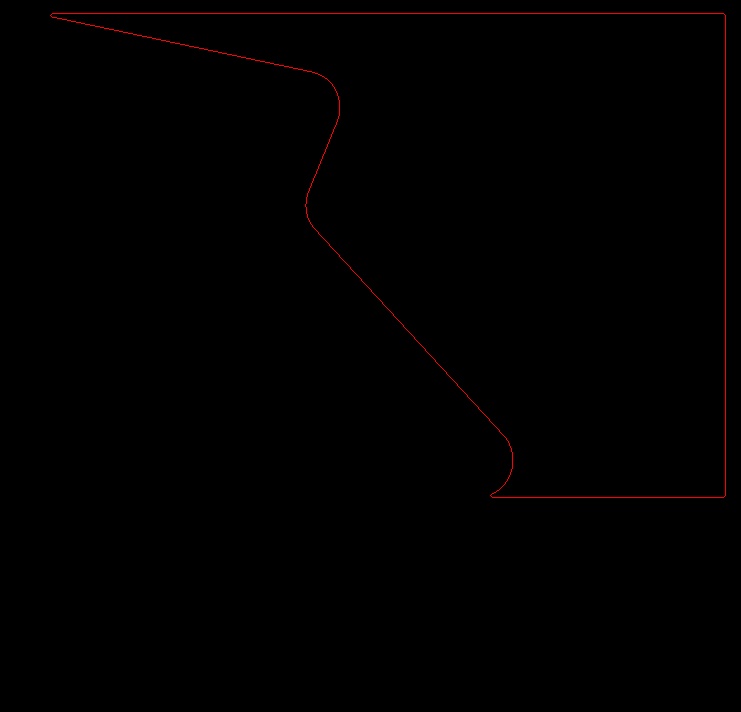
輸入的所有輪廓:

輪廓 1:

輪廓 2:

輪廓 3:

輪廓 4:
uj5u.com熱心網友回復:
以下是擦除文本的兩個選項:
- 使用 pytesseract OCR。
- 尋找白色(和小)連接組件。
兩種解決方案都構建了一個蒙版,擴大蒙版并cv2.inpaint用于擦除文本。
使用 pytesseract:
- 使用 查找文本框
pytesseract.image_to_boxes。 - 用 填充掩碼中的框
255。
代碼示例:
import cv2
import numpy as np
from pytesseract import pytesseract, Output
# Tesseract path
pytesseract.tesseract_cmd = "C:\\Program Files\\Tesseract-OCR\\tesseract.exe"
img = cv2.imread('ShortAndInteresting.png')
# https://stackoverflow.com/questions/20831612/getting-the-bounding-box-of-the-recognized-words-using-python-tesseract
boxes = pytesseract.image_to_boxes(img, lang='eng', config=' --psm 6') # Run tesseract, returning the bounding boxes
h, w, _ = img.shape # assumes color image
mask = np.zeros((h, w), np.uint8)
# Fill the bounding boxes on the image
for b in boxes.splitlines():
b = b.split(' ')
mask = cv2.rectangle(mask, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), 255, -1)
mask = cv2.dilate(mask, np.ones((5, 5), np.uint8)) # Dilate the boxes in the mask
clean_img = cv2.inpaint(img, mask, 2, cv2.INPAINT_NS) # Remove the text using inpaint (replace the masked pixels with the neighbor pixels).
# Show mask and clean_img for testing
cv2.imshow('mask', mask)
cv2.imshow('clean_img', clean_img)
cv2.waitKey()
cv2.destroyAllWindows()
面具:

查找白色(和小)連接組件:
- 用于
mask = cv2.inRange(img, (230, 230, 230), (255, 255, 255))查找文本(假設文本為白色)。 - 使用查找掩碼中的連接組件
cv2.connectedComponentsWithStats(mask, 4) - 從掩碼中洗掉大組件 - 用零填充大面積的組件。
代碼示例:
import cv2
import numpy as np
img = cv2.imread('ShortAndInteresting.png')
mask = cv2.inRange(img, (230, 230, 230), (255, 255, 255))
nlabel, labels, stats, centroids = cv2.connectedComponentsWithStats(mask, 4) # Finding connected components with statistics
# Remove large components from the mask (fill components with large area with zeros).
for i in range(1, nlabel):
area = stats[i, cv2.CC_STAT_AREA] # Get area
if area > 1000:
mask[labels == i] = 0 # Remove large connected components from the mask (fill with zero)
mask = cv2.dilate(mask, np.ones((5, 5), np.uint8)) # Dilate the text in the maks
cv2.imwrite('mask2.png', mask)
clean_img = cv2.inpaint(img, mask, 2, cv2.INPAINT_NS) # Remove the text using inpaint (replace the masked pixels with the neighbor pixels).
# Show mask and clean_img for testing
cv2.imshow('mask', mask)
cv2.imshow('clean_img', clean_img)
cv2.waitKey()
cv2.destroyAllWindows()
面具:

干凈的影像:

筆記:
- 我的假設是您知道如何將影像分割成輪廓,唯一的問題是文本的存在。
uj5u.com熱心網友回復:
我建議使用泛色填充,找到每個顏色區域的種子點,泛色填充以忽略其中的文本值。希望有幫助!
請參閱此處使用洪水填充的示例:https ://www.programcreek.com/python/example/89425/cv2.floodFill
下面的示例從上面的鏈接復制
def fillhole(input_image):
'''
input gray binary image get the filled image by floodfill method
Note: only holes surrounded in the connected regions will be filled.
:param input_image:
:return:
'''
im_flood_fill = input_image.copy()
h, w = input_image.shape[:2]
mask = np.zeros((h 2, w 2), np.uint8)
im_flood_fill = im_flood_fill.astype("uint8")
cv.floodFill(im_flood_fill, mask, (0, 0), 255)
im_flood_fill_inv = cv.bitwise_not(im_flood_fill)
img_out = input_image | im_flood_fill_inv
return img_out
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/461997.html