嘗試使用 tesseract 讀取一些資料,但它已經在日期和時間上苦苦掙扎,所以我創建了一個最小的測驗用例。
代碼:
#include <string>
#include <sstream>
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc.hpp>
#include <boost/algorithm/string/trim.hpp>
using namespace std;
using namespace cv;
int main(int argc, const char * argv[]) {
string outText, imPath = argv[1];
cv::Mat image_final = cv::imread(imPath, CV_8UC1);
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
api->Init(NULL, "eng", tesseract::OEM_LSTM_ONLY);
api->SetPageSegMode(tesseract::PSM_AUTO_ONLY);
cv::adaptiveThreshold(image_final,image_final,255,ADAPTIVE_THRESH_MEAN_C, cv::THRESH_BINARY,11,2);
api->SetImage(image_final.data, image_final.cols, image_final.rows, 3, image_final.step);
api->SetVariable("tessedit_char_whitelist", "0123456789- :");
outText = string(api->GetUTF8Text());
api->End();
std::istringstream iss(outText);
for (std::string line; std::getline(iss, line); ) {
boost::algorithm::trim(line);
if (!line.empty()) cout << line << endl;
}
cv::imwrite("out.png", image_final);
return 0;
}
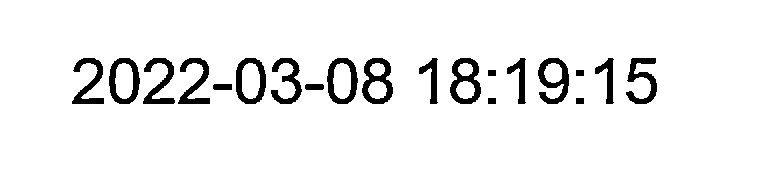
輸出:
1122-03-08 18:10
2122-030 18:10
我什至嘗試將這些字符列入白名單(最終版本中不會出現這種情況),但結果仍然很糟糕。
uj5u.com熱心網友回復:
看起來主要問題是設定bytes_per_pixel為3而不是1in api->SetImage。
之后的影像cv::adaptiveThreshold是 1 個顏色通道(每像素 1 個位元組)而不是 3 個。
替換api->SetImage(image_final.data, image_final.cols, image_final.rows, 3, image_final.step);為:
api->SetImage(image_final.data, image_final.cols, image_final.rows, 1, image_final.step);
替換cv::imread(imPath, CV_8UC1)為cv::imread(imPath, cv::IMREAD_GRAYSCALE)
您也可以嘗試用tesseract::PSM_AUTO_ONLYortesseract::PSM_AUTO替換tesseract::PSM_SINGLE_BLOCK。
根據頭檔案中的注釋:
PSM_AUTO_ONLY = 2, ///< 自動頁面分割,但沒有 OSD 或 OCR。
(除非這是故意的——我從未使用過 C 介面)。
我嘗試使用 pytesseract 和 Python 重現該問題,但將 PSM 設定為 2 時出現錯誤。
我可能也在使用不同版本的 Tesseract。
結果是完美的,它應該與您帖子中的影像完美。
Python代碼:
import cv2
from pytesseract import pytesseract
# Tesseract path
pytesseract.tesseract_cmd = "C:\\Program Files\\Tesseract-OCR\\tesseract.exe"
img = cv2.imread("out.png", cv2.IMREAD_GRAYSCALE) # Read input image as Grayscale
text = pytesseract.image_to_string(img, config="-c tessedit"
"_char_whitelist=' '0123456789-:"
" --psm 3 "
"lang='eng'")
print(text)
輸出:
2022-03-08 18:19:15
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/462002.html