我是一名 Python 新手,正在構建一個網路爬蟲來從網站獲取資料,這樣我就可以在最便宜的時候購買電力。問題是我需要的資料在腳本中,我可以使用 Beautiful Soap 來獲取它嗎?我現在嘗試了很多不同的方法,在這里可能真的需要一些幫助。我要抓取的頁面是https://www.elbruk.se/timpriser-se3-stockholm ,我需要的資訊在下面的資料串列中。
const labels = [
'00:00','01:00','02:00','03:00','04:00','05:00','06:00','07:00','08:00','09:00','10:00','11:00','12:00','13:00','14:00','15:00','16:00','17:00','18:00','19:00','20:00','21:00','22:00','23:00','24:00',];
const data = {
labels: labels,
datasets: [{
stepped:true,
label: 'Idag',
backgroundColor: '#357DA7',
borderColor: '#357DA7',
data: [94.24,91.59,93.52,97.70,103.23,155.15,233.20,269.03,279.92,255.87,231.30,226.70,209.64,174.65,164.84,154.16,134.04,199.48,205.03,204.88,192.49,154.16,74.40,19.47,19.47]
},
(頁面代碼中的第 494 行)是否可以用 Beautiful Soap 提取它,還是我在這里陷入了死胡同?也許用 Json 決議它?也沒有提供資訊 API 的站點..(我的第一個希望..)
uj5u.com熱心網友回復:
一個簡單(但不完美)的解決方案是遍歷所有腳本并找到包含“const labels =”的腳本,然后您只需修剪掉不需要的文本并決議串列
uj5u.com熱心網友回復:
BeautifulSoup 不是必需的,因為最后你需要用正則運算式替換很多,因為它不是有效的 json
import requests
import re
import json
response = requests.get(theURL)
data = re.search(r'data\s=\s(\{[^;] )', response.text)
data = data[1].replace("'", '"') # 'Idag' -> "Idag"
data = data.replace(",]", ']') # ,] -> ]
data = re.sub(r"(\w ):", r'"\1":', data) # labels: labels -> "labels": labels
data = re.sub(r":\s?(\w )", r':"\1"', data) # "labels": "labels"
data = json.loads(data)
print(data['datasets'][0]['backgroundColor'])
# print(json.dumps(data, indent=2))
uj5u.com熱心網友回復:
就這樣做。
使用python下載源代碼,然后用這個正則運算式(下面的字串)決議它,然后取它找到的第一個匹配項
/^const labels(.*)const config = {type: 'line',data: data,options: {}};/gmis
這里的例子
uj5u.com熱心網友回復:
假設您只想要該圖表的標簽和值,您可以將它們正則運算式,將兩者都作為串列,然后變成字典。
import re, requests, ast
r = requests.get('https://www.elbruk.se/timpriser-se3-stockholm')
idag = dict(zip([i[0] for i in re.findall(r"'((2[0-4]|[01]?[0-9]):([0-5]?[0-9]))'", r.text)],
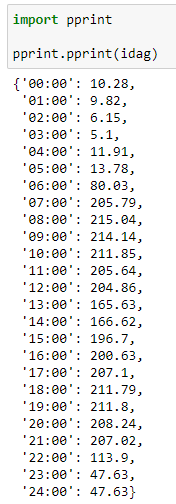
ast.literal_eval(re.search(r"data: .*(\[.*?\])[\s\S] (?='Idag snitt')", r.text).group(1))))
print(idag)
我從 Jan Goyvaerts 和 Steven Levithan 的 O'Reilly Regular Expressions Cookbook, 2nd Edition 改編了 24 小時的正則運算式。
第一個正則運算式獲取 24 小時時鐘時間。第二個正則運算式data: 用作開始文本,然后在(使用正向前瞻)文本之前提取數字陣列Idag snitt。ast用于將字串串列/陣列轉換為 python 串列。
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/464524.html
標籤:Python python-3.x 美丽的汤 脚本